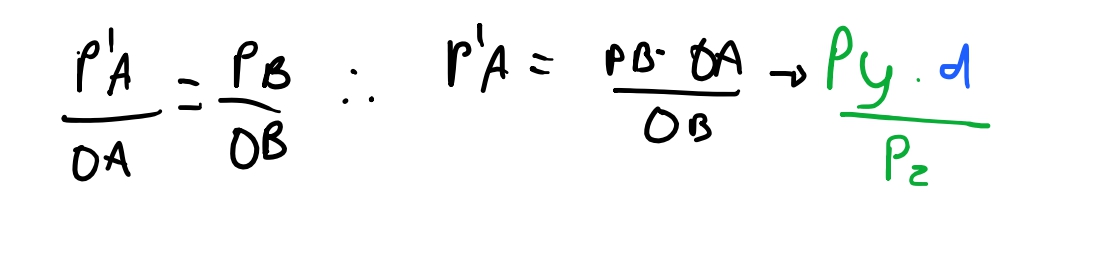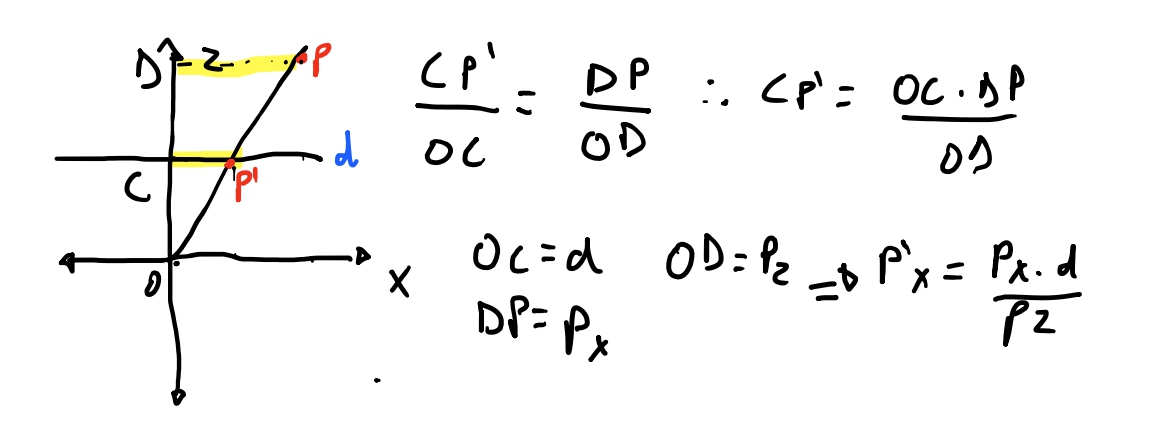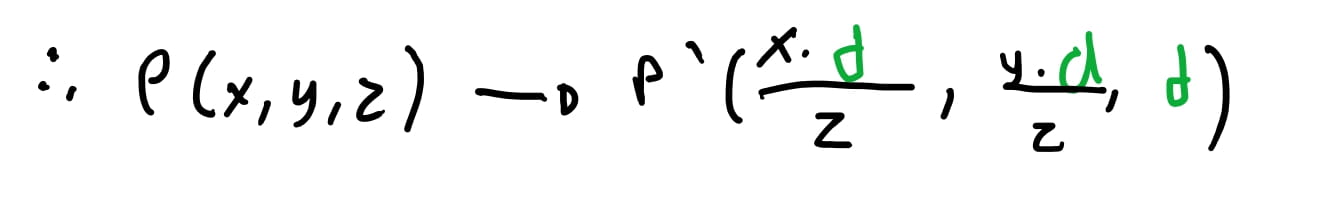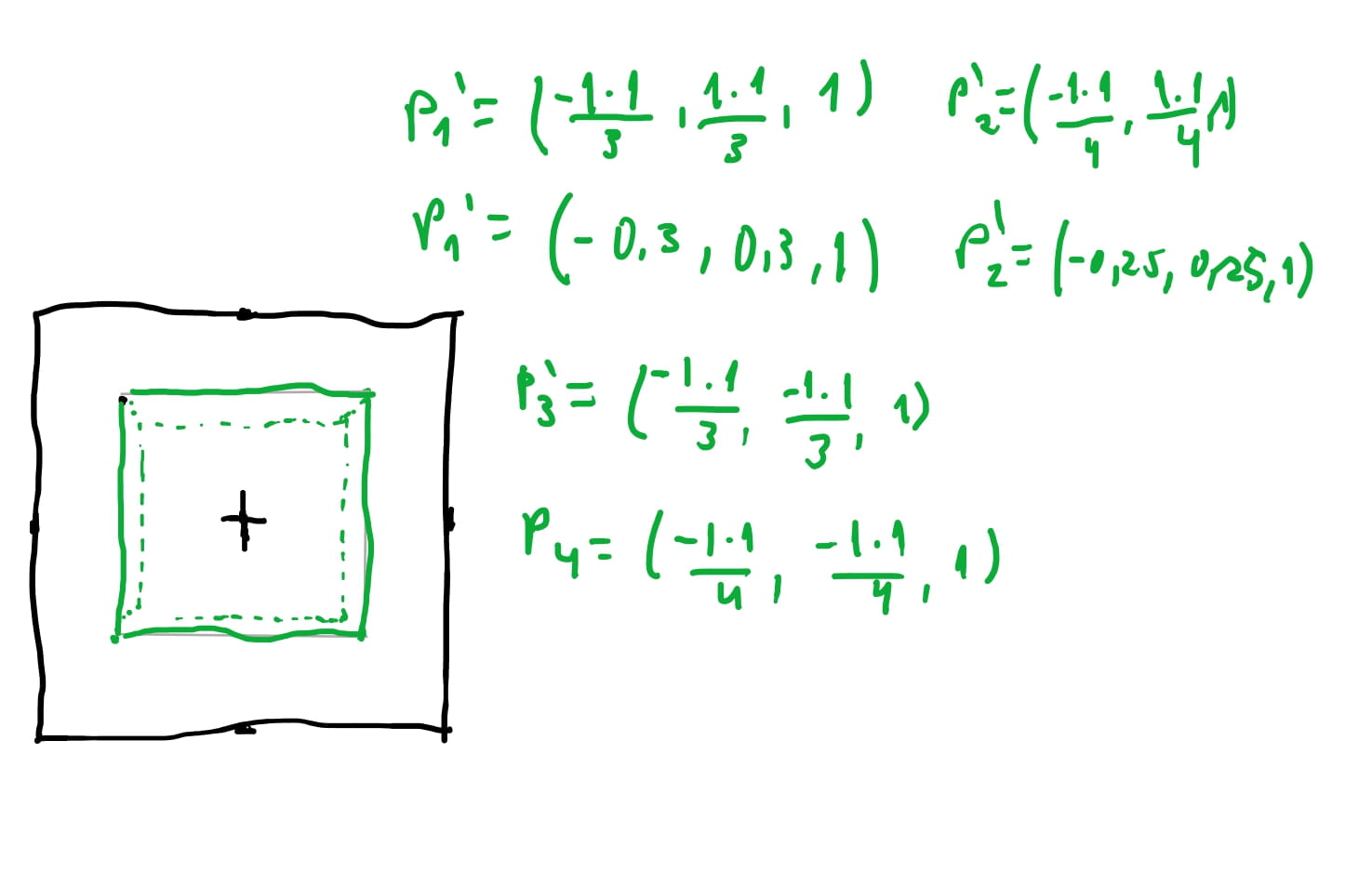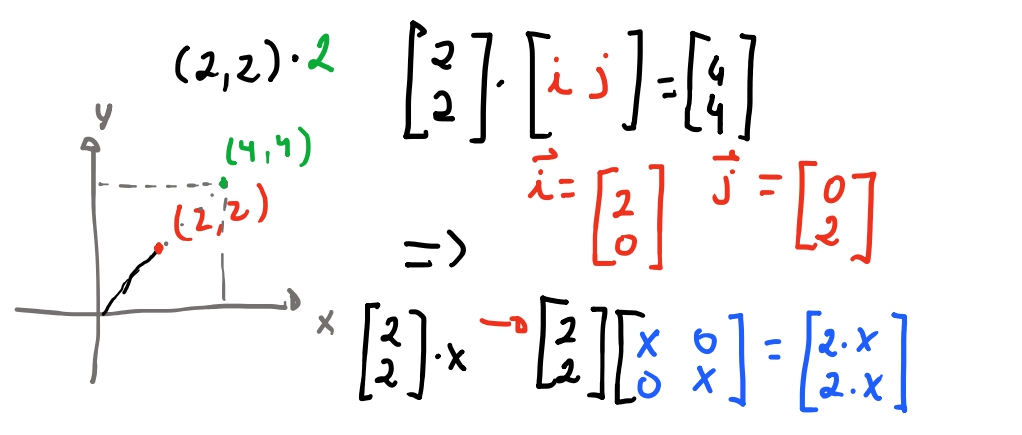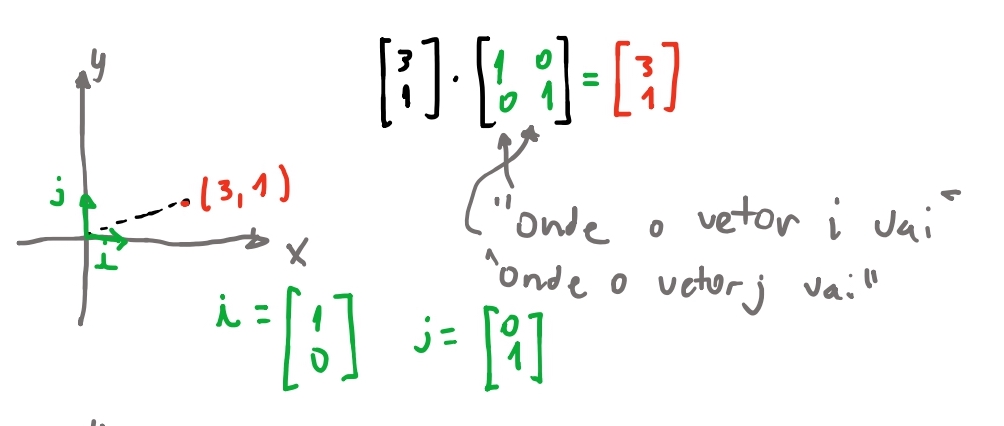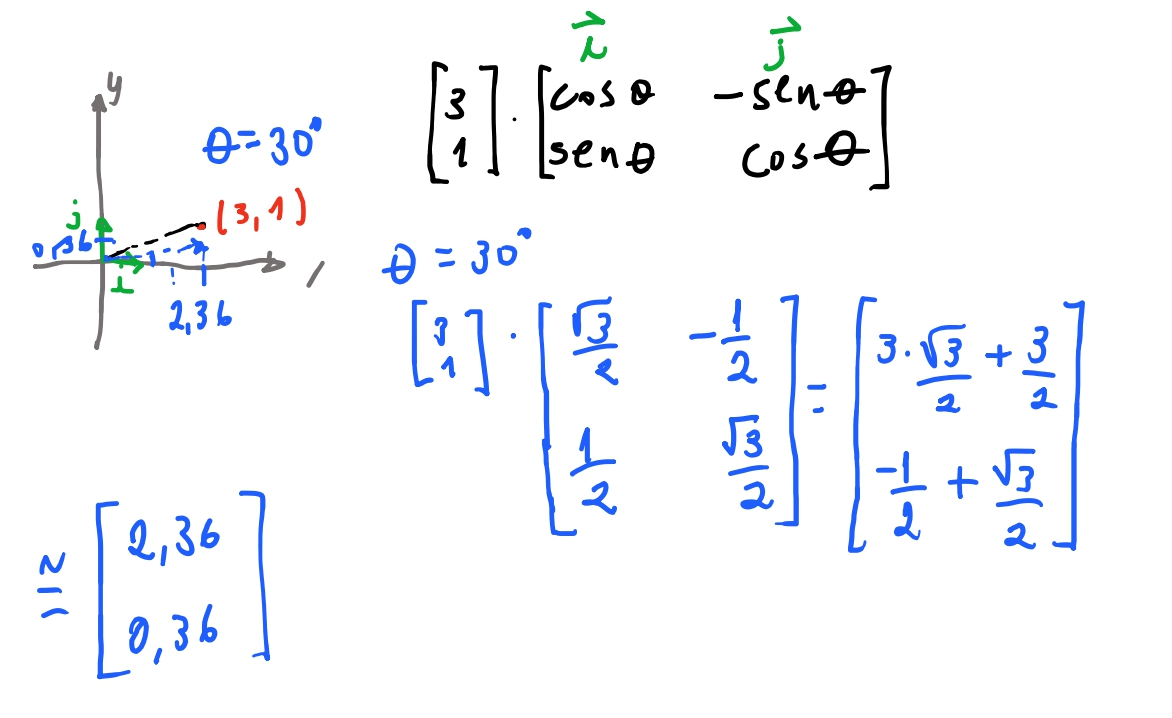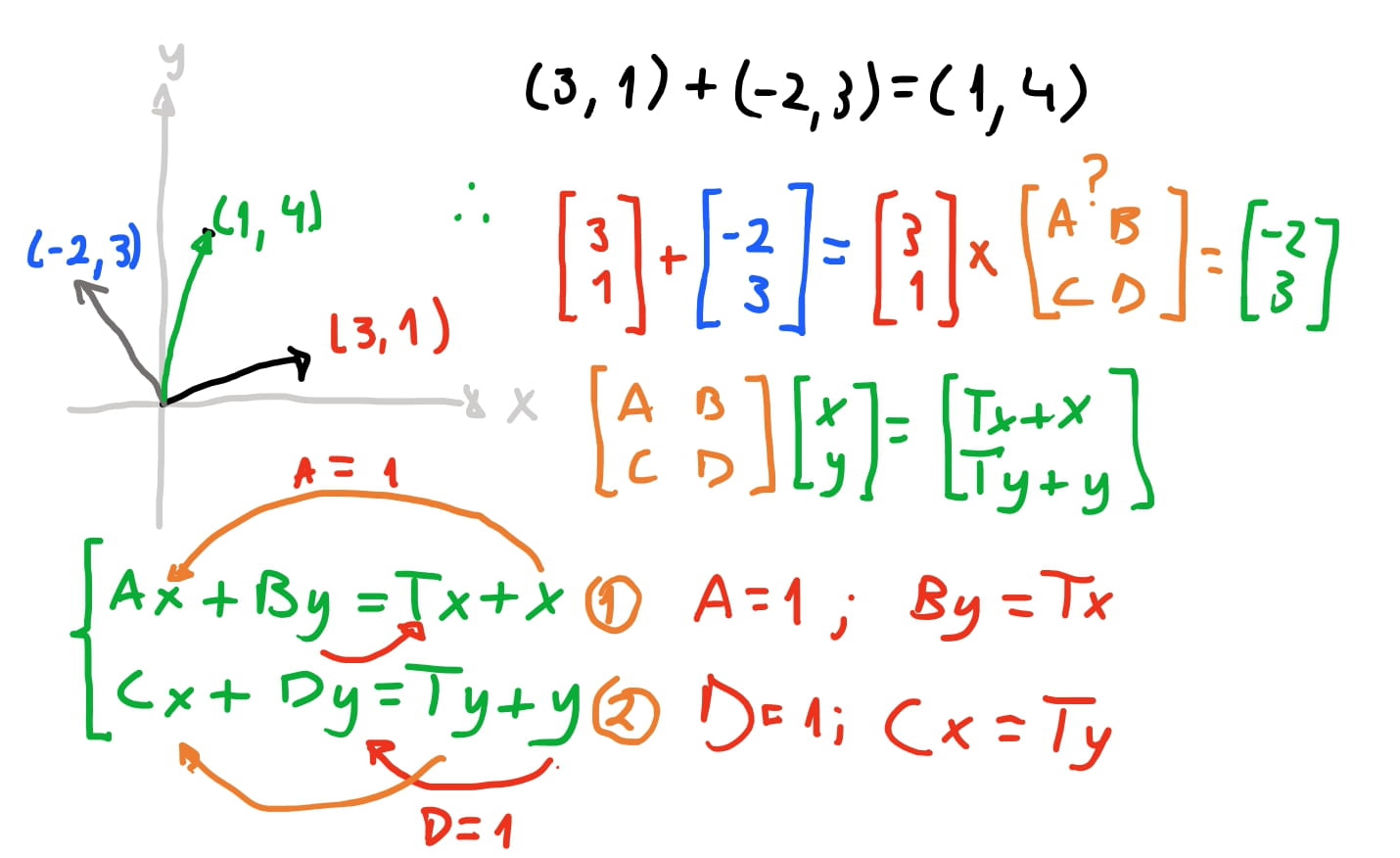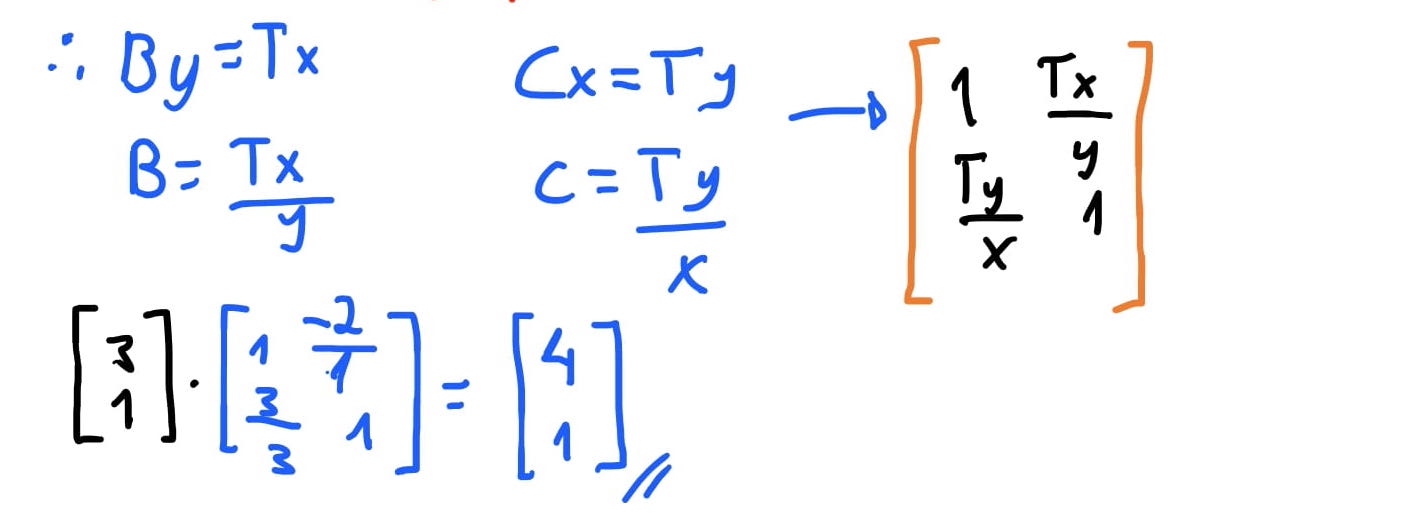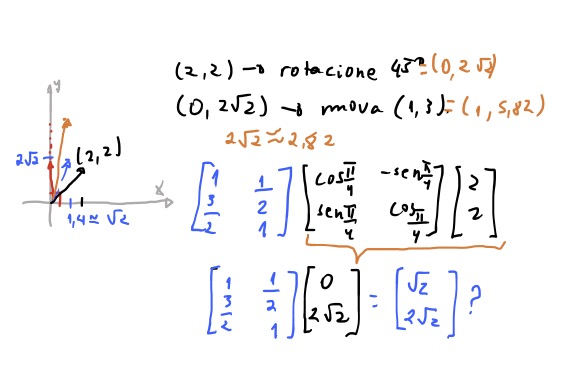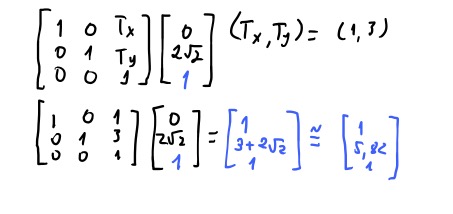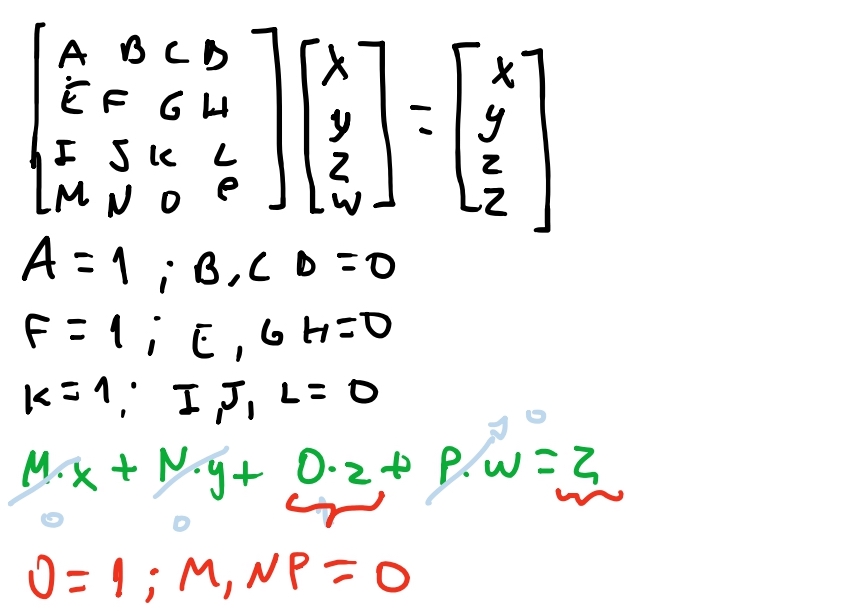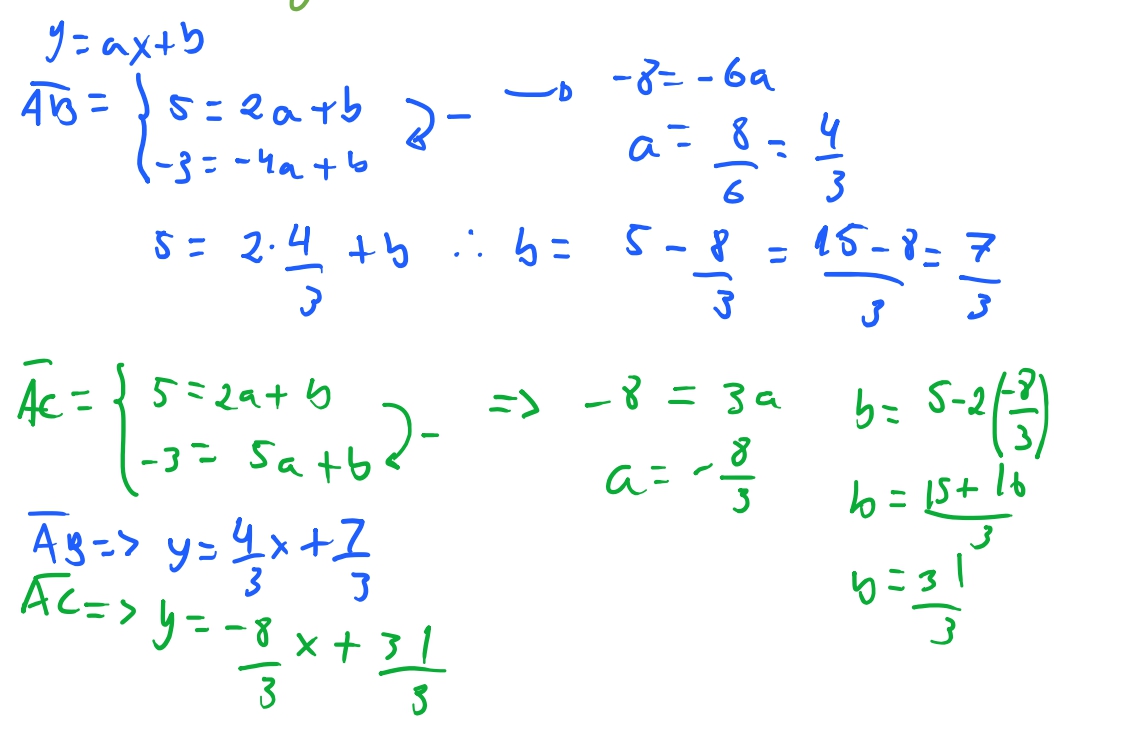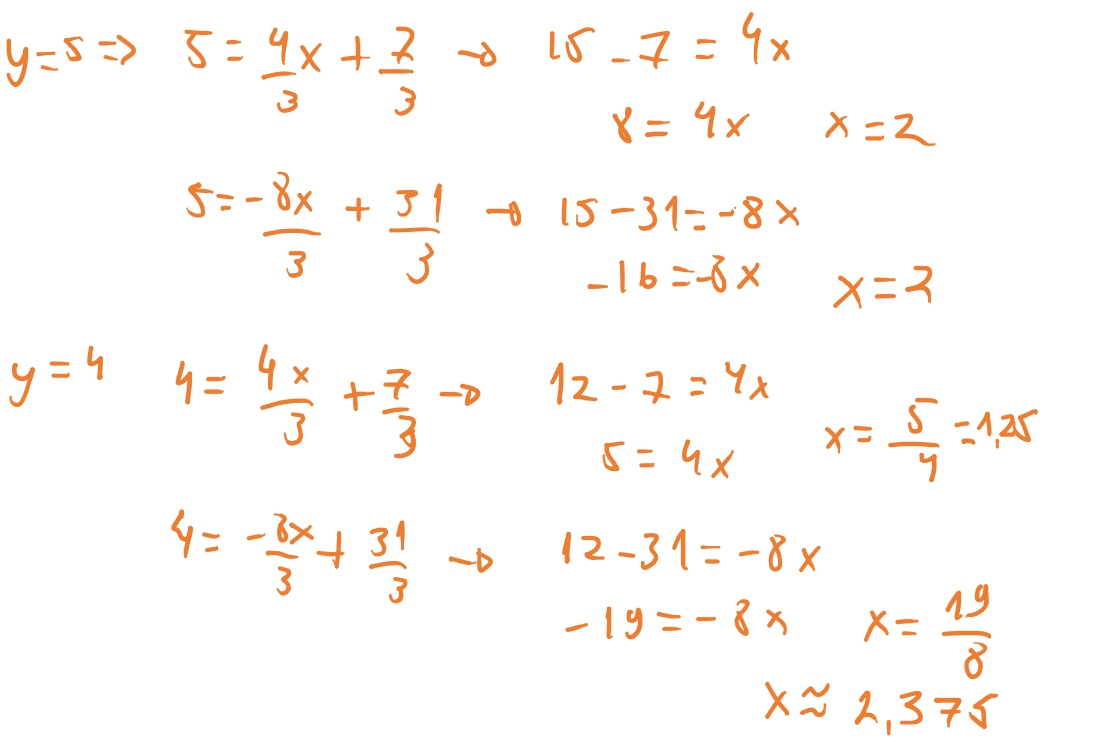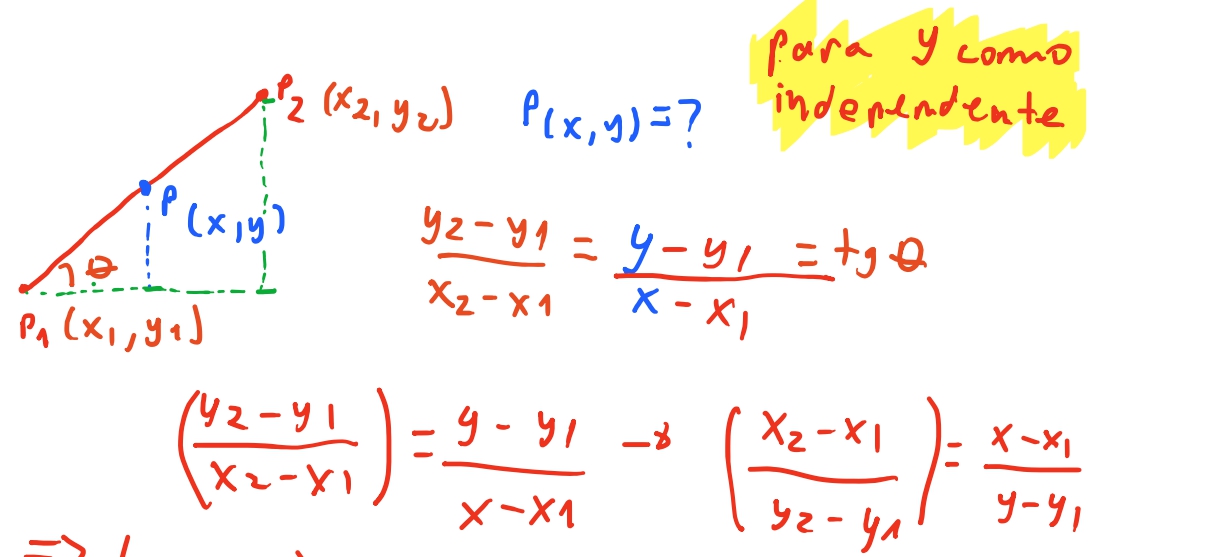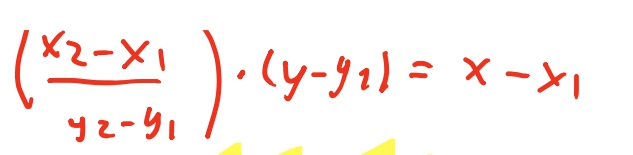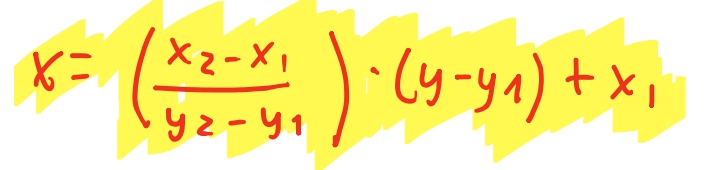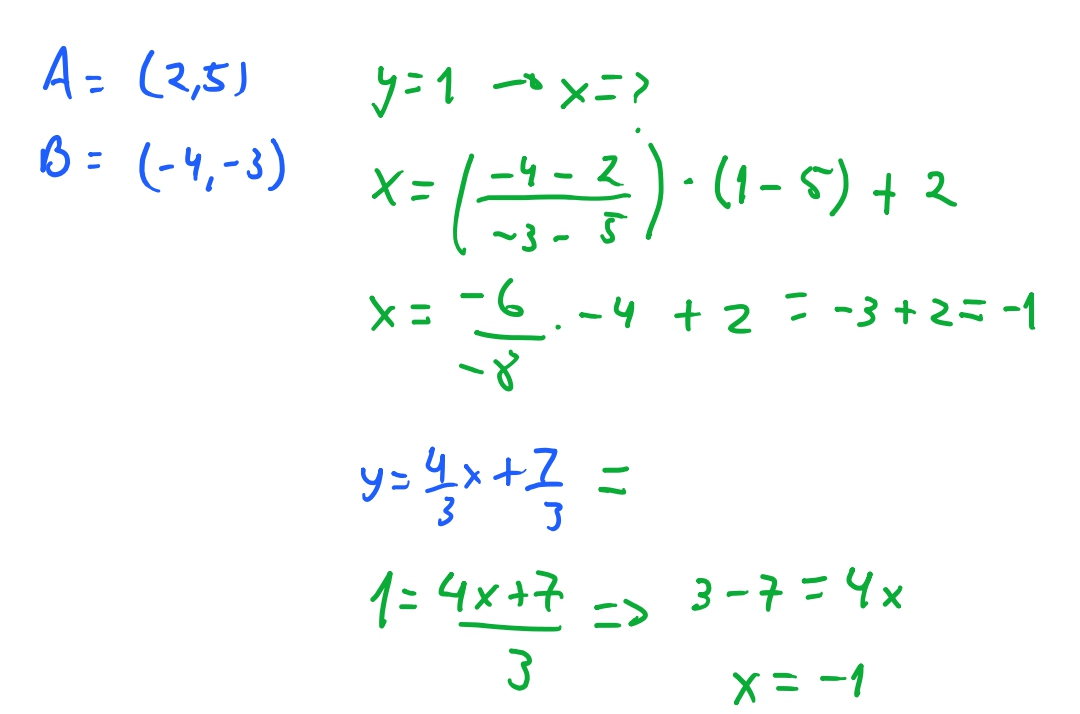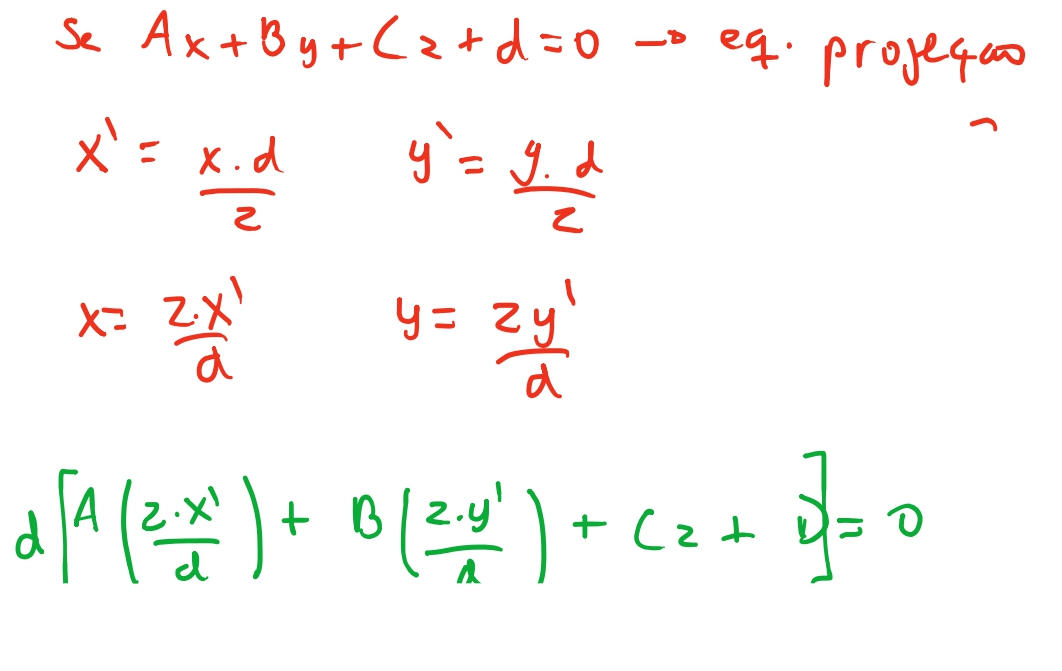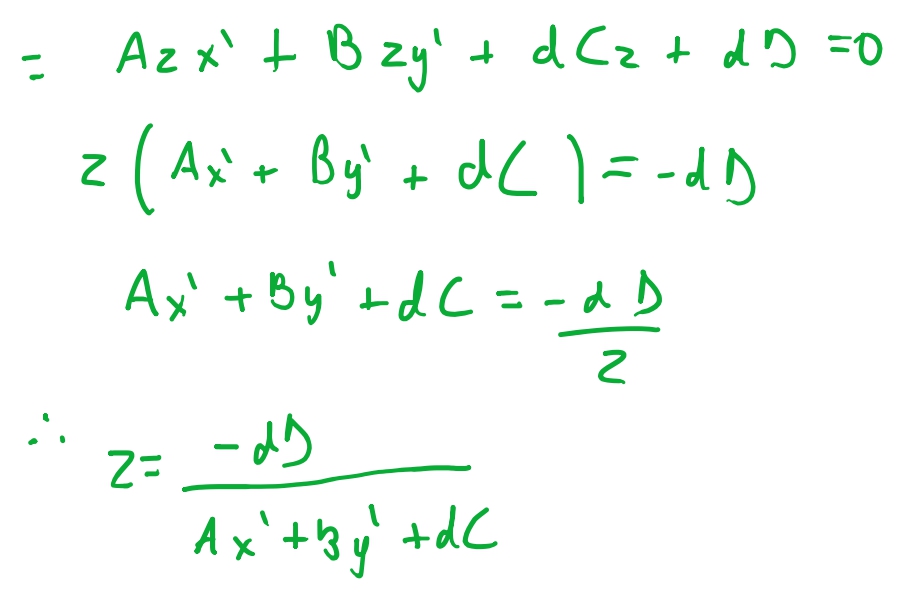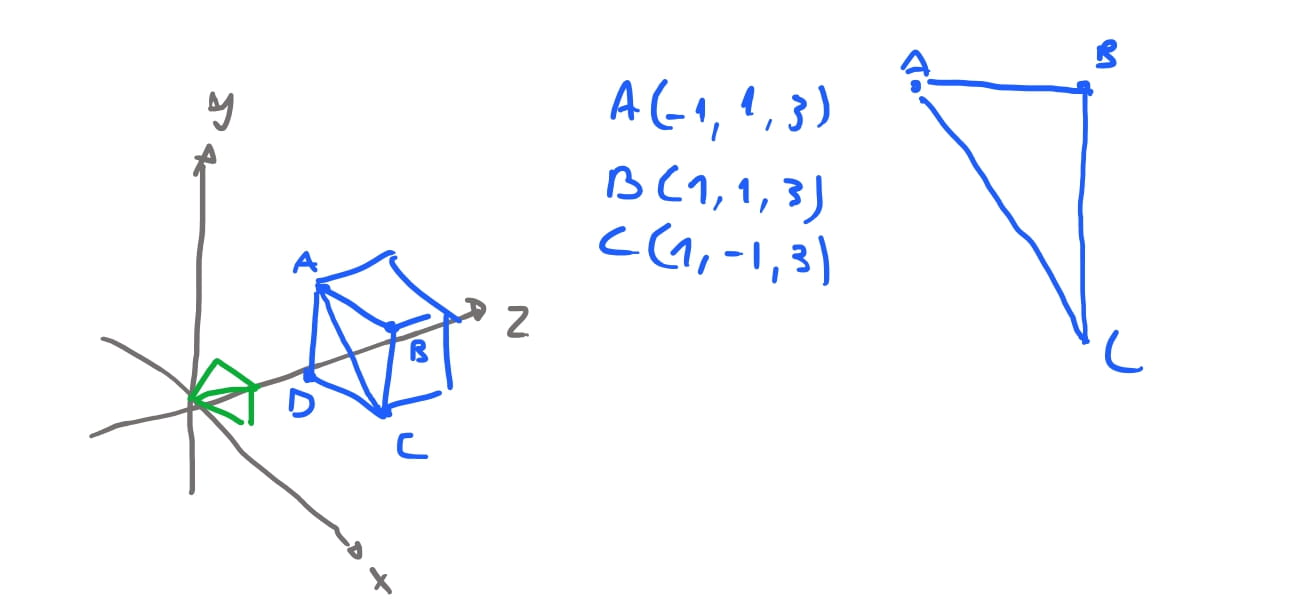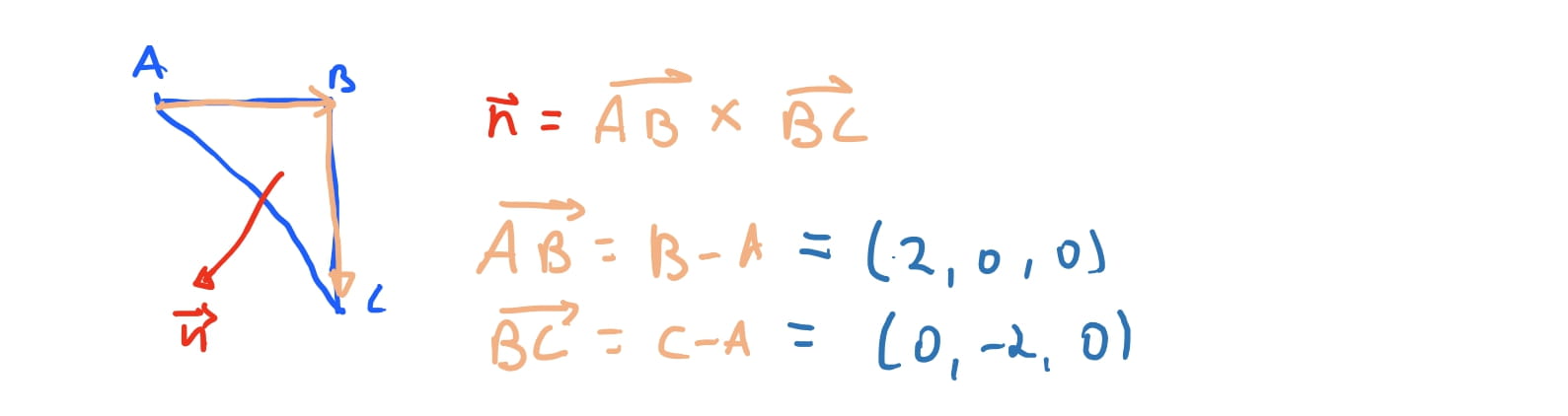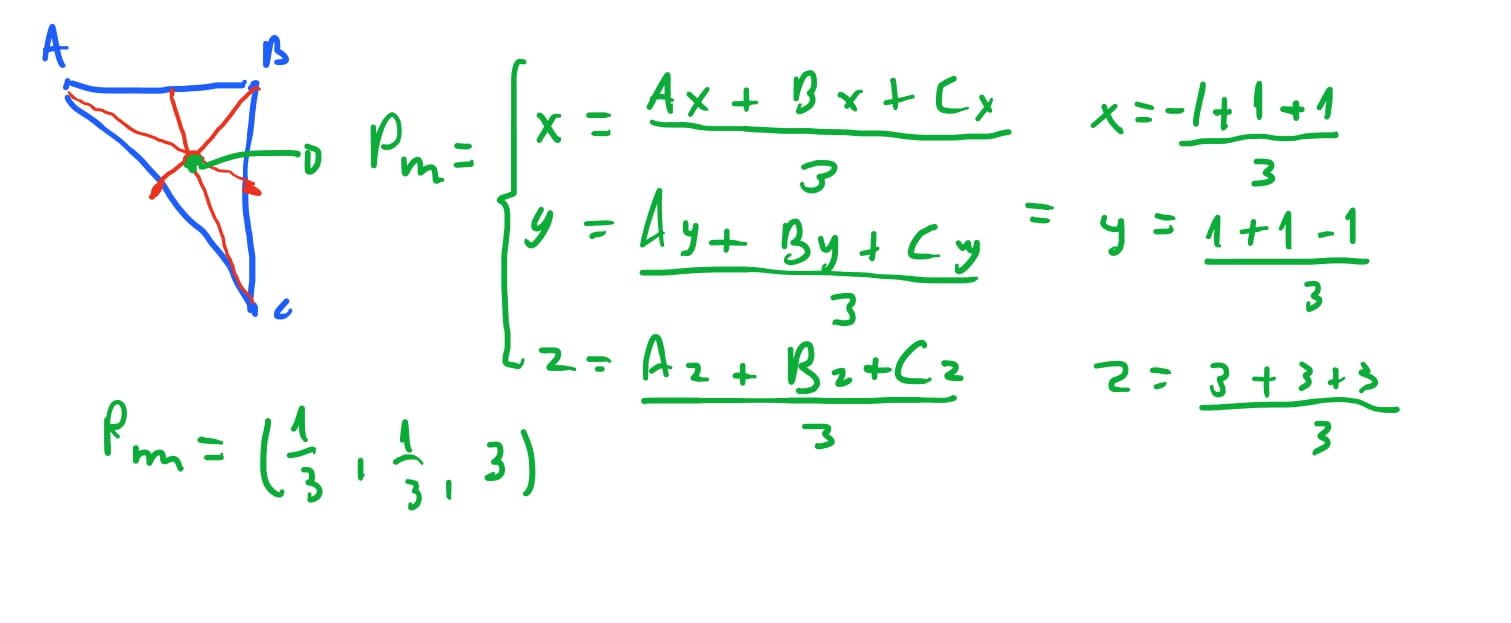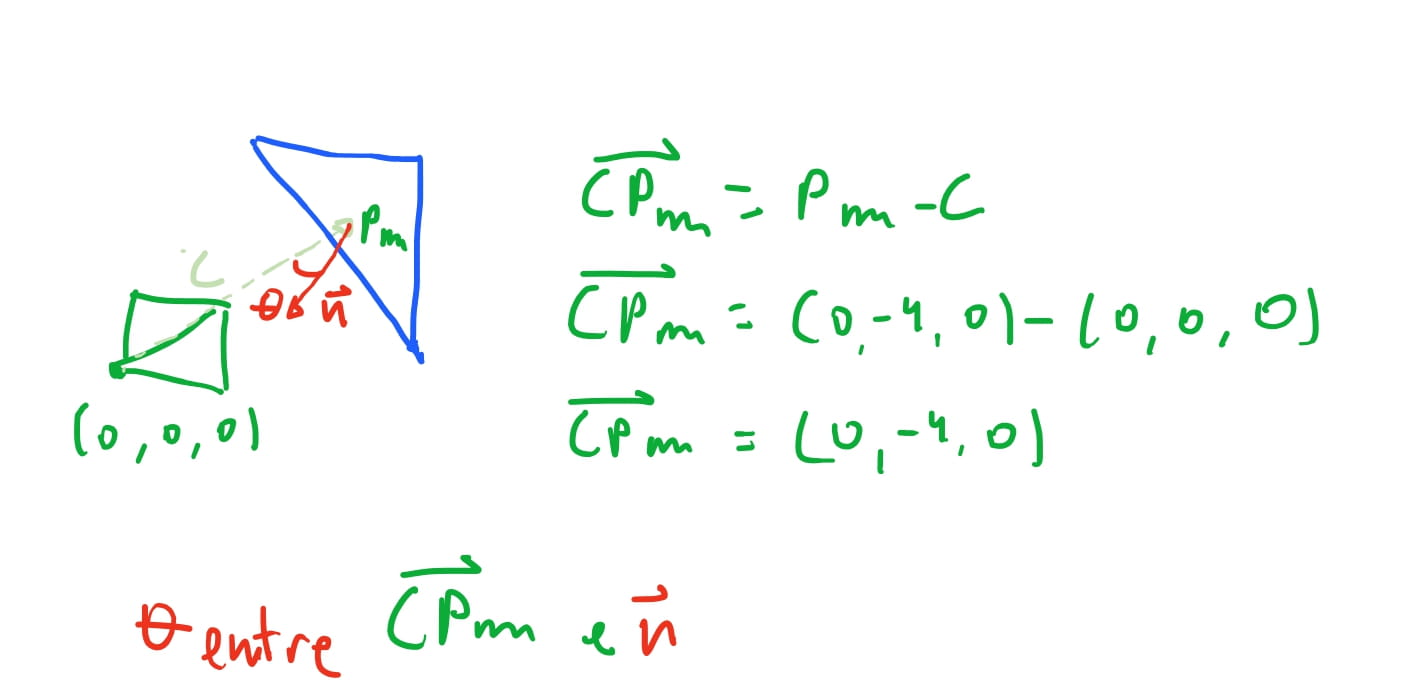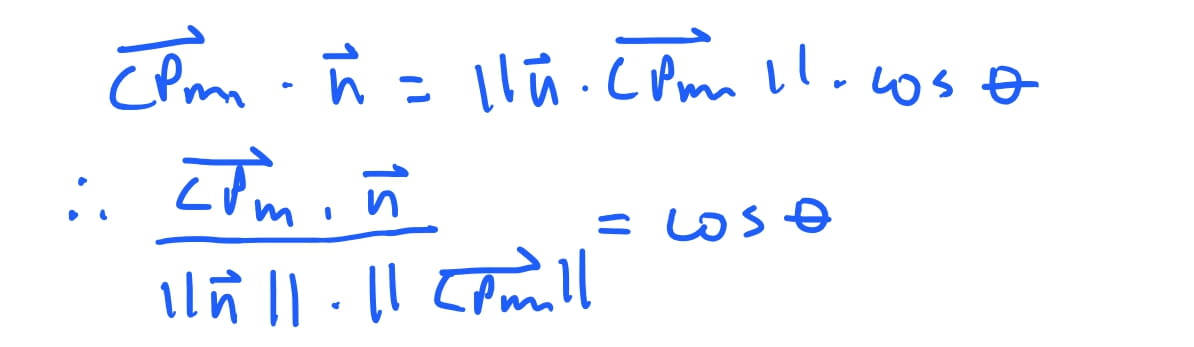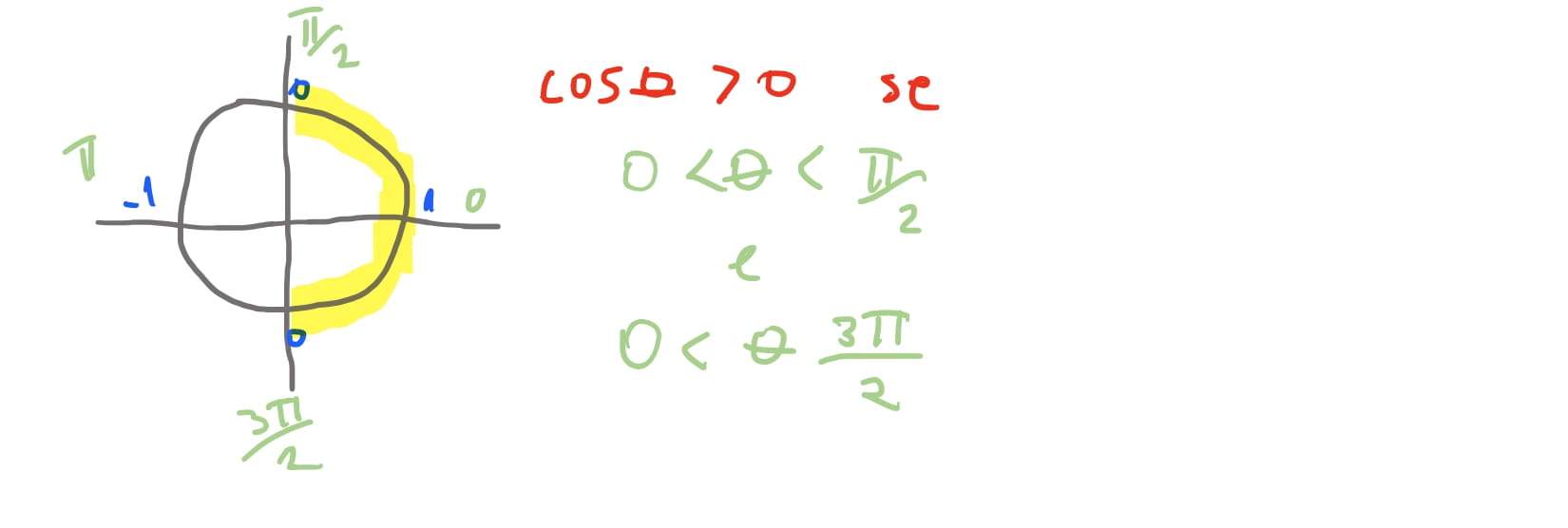Decidi escrever este texto em português porque pensei: “hmmm.. acho que ja existe material mais que suficiente em ingles, mas para o publico brasileiro existe pouco material” e eu pensei no pequeno eu com 12 anos que queria entender como computação gráfica funcionava e não tinha acesso nem a livros bem escritos quanto compreensão de ingles o suficiente.
Então pensando nisso, decidi escrever em português
O que você deve esperar?
Daqui em diante eu quero te levar em uma sequencia de textos para desmistificar algumas ideias de matemática e computação. A ideia é te mostrar que tudo pode ser mais simples. Eu vou mostrar os cálculos e como chegar neles e acho que essa forma de “abrir” e “levantar os véus” Apokalipsis é o melhor jeito de aprender sobre um assunto.
O texto irá da ideia simples de como desenhar um pixel na tela, e seguiremos a sequencia de: como desenhar uma linha, como desenhar um triangulo, como preencher este triangulo, como desenhar uma figura tridimensional projetada em uma superfície bidimensional, e preencher com o mesmo algoritmo de triângulos, como colocar perspectiva nos triângulos que iremos desenhar.
Com isto tudo em mente nos próximos textos vamos abortar as bibliotecas gráficas que conversam com a placa de video e fazem tudo isso para o desenvolvedor e de forma rápida.
O que voce precisa saber?
Gostaria que ninguém precisasse saber nada. Não precisa perfeitamente confortável com matemática, mas caso não seja o caso, eu peço que acompanhe genuinamente os cálculos e vou explicar o mais sucintamente que puder e talvez voce possa desenvolver certa facilidade. Não é nada extraordinariamente mais avançado do que uma aula de matemática normal, apenas sendo “aplicado”.
What about english?
Yea, my previous text were in english, and I plan to translate this one to english too, so wait for it, or … google translate this one. But .. there is already plenty material, which will be quoted at the end of this text so you can have some sources of your own.
Começando do começo: como desenhar uma linha ?
“Dê-me uma alavanca e um ponto de apoio e eu moverei o mundo” essa frase de Arquimedes poderia ser facilmente aplicada para a computação gráfica: “Dê-me uma função de desenhar retas e eu irei desenhar qualquer forma”. A ideia por trás disso é que se pudermos desenhar livremente linhas com o controle fino que quisermos, podemos decompor qualquer figura em desenho de linhas.
Então espero ter justificado o porque dos próximos parágrafos e com esse argumento espero que acompanhe sem muita reclamação e tédio os próximos parágrafos que estão vindo.
um pouquinho de matematica
Vamos imaginar que queremos desenhar uma reta no plano entre dois pontos.
A tela de um computador (como vista no texto de raytracing) é representada como a imagem acima: (eixo \(x\) cresce para direita, e o eixo \(y\) cresce para baixo.
Então vamos imaginar como vamos desenhar um ponto na tela usando este tipo de coordenada
Então como na imagem acima temos \(P_0\) e queremos desenhar uma linha até \(P_1\). Podemos pensar que podemos pegar qual a direção para o \(P_1\) à partir de \(P_0\) e pintar cada pixel naquela direção e então, fazemos isso até chegar em \(P_1\).
Representando esta ideia matematicamente queremos dizer que um ponto \(P\) na reta entre \(P_0\) e \(P_1\) vai ser igual à \(P = P_0 + \vec{v} * t\) onde \(t\) vai ser um numero qualquer. Ou seja, se \(t = 0\), \(P\) vai ser igual a \(P_0\). Se \(t=1\), então \(P\) vai ser igual \(P_1\). Então modelamos uma equação que modela essa reta entre os dois pontos porem \(t\) tem que estar entre \(0 e 1\).
Na imagem acima vemos um exemplo de como usamos esta equação que modelamos para encontrar um ponto na reta. Fizemos \(t = 0.5\) e encontramos um ponto na reta \(l\) em que \(P = (5.5, 5.5)\).
Porem como podemos fazer para encontrar os pixels na tela? Vamos lembrar que o pixel é “discreto”. Quando digo “discreto” digo que é um valor “inteiro”, ou seja, o pixel \((5.5, 5.5)\) não existe na tela, apenas o pixel \((5,5)\). Então se fizéssemos uma função como iterar entre 0 e 1 e incrementar \(0.01\), Iteraríamos mil vezes e repetiríamos muitos valores: Todos valores entre \(5.001\) e \(5.599\) seriam o mesmo pixel. Talvez não pareça tão ruim agora mas imagine que vamos usar esta mesma função para preencher triângulos e no futuro cada polígono tridimensional vai ter milhares de triângulos, então ja imagine o quanto essa função vai fazer o computador trabalhar atoa.
OBS: Se você é um programador de primeira viagem, recomendo a leitura do texto Why early optimization is the root of all evil em que o autor alerta sobre optimização prematura do código. O que estamos fazendo aqui pode ser um exemplo de optimização prematura ja que antes mesmo de acontecer o problema de custo computacional ja estamos corrigindo ele. Porem, estou me atendo a este ponto agora pois acho didático lidar com a ideia do algoritmo de desenho de linhas e deixar este problema fora de vista para os problemas que virão futuramente!
Então vamos tentar melhorar nossa equação. Queremos saber apenas os pontos que estão na reta ( o que nossa equação atualmente ja nos oferece), porem, queremos apenas as coordenadas “discretas”. E além disso, queremos fazer o mínimo de iterações possíveis. De preferencia, pra cada valor de \(x\) a equação retorne um valor de \(y\) ou vice-versa. Como podemos fazer isso ??
Então vamos estender um pouco nossa equação. Sabemos que \(P = (x,y)\), ou seja, um ponto é um conjunto de coordenadas no plano \(x,y\).
Decompomos então a nossa equação em \((x,y) = (x_0, y_0) + t * ( x_1 - x_0 , y_1 - y_0)\). O motivo dessa subtração é que para encontrar a direção de um ponto para o outro (chamamos essa direção de vetor) fazemos \(ponto Final - ponto Inicial\) e isto nos dá o “vetor” que aponta do ponto inicial para o ponto final.
E então, com a nossa equação decomposta em \((x,y)\), vamos separar por variável e separáramos em um sistema de equações. \(x = x_0 + t (x_1 - x_0)\) e similar para \(y\).
Vamos isolar então a única variável em comum às duas equações \(t\). E então vamos substituir o que encontrar-mos como valor de \(t\) na segunda equação. Assim vamos chegar em apenas uma equação com as duas variáveis. Lembrando que o nosso objetivo é chegar em uma equação que nos dê o valor de \(y\) para cada \(x\).
Isolando o \(t\) encontramos que \(t = \dfrac{x - x_0}{x_1 - x_0}\)
Fazendo a substituição do nosso valor de \(t\) na equação de \(y\) encontramos que \(y = y_0 + \dfrac{x-x_0}{x_1 - x_0} * (y_1 - y_0)\).
Mas como sabemos que iniciamos em \(P_0\) e vamos para \(P_1\), então significa que temos os valores de ambos os pontos. Então vamos chamar \(\dfrac{y_1 - y_0}{x_1 - x_0}\) de \(a\) porque sabemos que o valor desta divisão é constante. Ou seja, assim que definimos os dois pontos, sabemos qual o valor de \(a\). No nosso exemplo la de cima, em que \(P_0 = (3,5)\) e \(P_1 = (8,6)\), teríamos que \(a = \dfrac{6-5} {8-3} = \dfrac{1}{5}\).
Percebemos também que se fizermos a multiplicação de \(a\) por \((x-x_0)\) restante, encontramos outras constantes: \(y_0\) e \(-a * x_0\). Que vamos chamar de \(b\).
Resultando na equação de reta. Nesta equação conseguimos obter um valor de \(y\) para cada valor de \(x\) entrado.
Vamos para um exemplo
Para \(x = 1\) constatamos que o \(y = 3\), ou seja, confirmamos a posição de \(P_0\).
Então vamos escrever nosso pseudo código pra escrever linhas, lembrando que temos apenas uma função disponível da tela que é putPixel(x, y, color) como visto no post anterior.
function drawLine(p0, p1, color):
a = p1.y - p0.y / p1.x - p0.x
b = p0.y - a * p0.x
for x = p0.x ; x <= p1.x; x++:
y = a*x + b
putPixel(x, y, color)
No qual nossa função apenas recria o comportamento da função que encontramos e faz um laço entre \(x\) de \(P_0\) e \(x\) de \(P_1\).
Porem, ao implementarmos o código acima nos deparamos com os seguinte bug:
Quanto mais inclinada é a reta, teremos, como no exemplo acima, apenas um valor de \(x\) para vários pixels no eixo \(y\). Se a reta for completamente vertical, ou seja, o valor da coordenada \(x\) do ponto inicial e final é o mesmo, simplesmente não há iteração e logo não há nenhum pixel para ser colorido.
Apesar de haver apenas um valor de \(x\) para calcular algum pixel entre os dois pontos, há uma distancia de \(y\) dos dois pontos.Sendo os pontos \(P_0 = (5,1)\) e \(P_1 = (7,10)\), haveriam 9 valores em \(y\) para encontrarmos valores de \(x\). Poderíamos então procurar valores de \(x\) para cada valor de \(y\). Seria o inverso da função !
Vamos ver como faríamos isso!
Então imagine que “rotacionamos” a tela, e considere que trocamos os eixos \(x\) e \(y\). Poderíamos calcular qual valor de \(y\) para uma coordenada do pixel \(x\) dos pontos “invertidos”, sendo \(P_0 = (1, 5)\) e \(P_1 = (10,7)\). E usaríamos a mesma equação.
Agora que conseguimos encontrar uma equação independente da inclinação da reta, precisamos de um critério de quando vamos usar uma ou outra.
Podemos fazer um exercício mental: Imaginemos o angulo da reta (formador pelos pontos \(P_0\) e \(P_1\)) e o eixo \(x\). Quando este angulo é \(0 °\), há o máximo de pixels na horizontal. E quando este angulo é \(90 °\) o numero pixels é nulo. Mas em \(90 °\) o numero de pixels em \(y\) é o máximo.
Então podemos dividir pela metade, e de \(0 °\) até \(45 °\) usamos \(x\) e de \(45 °\) até \(90 °\) usamos \(y\).
Vamos testar nossa hipótese e implementar nosso pseudocódigo desenvolvido até agora!
Como vimos, precisamos saber apenas se há mais pixels para iterar ou pelo eixo \(y\) ou pelo eixo \(x\). Então ao invés de consultamos por ângulos, podemos consultar pela “diferença” de pixels. O eixo que possuir mais pixels para iterar-mos será o eixo escolhido.
Podemos pensar que nosso angulo é a “razão” do quanto um eixo aumenta em relação ao outro. Quanto maior o angulo, mais rápido \(y\) aumenta quando \(x\) aumenta.
function drawLine(p0, p1, color):
dx = abs(p1.x - p0.x)
dy = abs(p1.y - p0.y)
a = dy/dx
b = p0.y - a* p0.x
if dx > dy:
for x=p0.x; x<=p1.x; x++:
y = a*x + b
putPixel(x, y, color)
else:
for y=p0.y; y<=p1.y; y++:
x = (y-b)/a
putPixel(x, y, color)
O problema de usar \(\frac{y-b}{a}\) é que \(a\) vai ser uma divisão por zero quando a reta estiver “vertical”. Para isso vamos “inverter” a nossa equação em função de \(y\).
Estamos quase lá! Nosso algoritmo de linhas ainda tem um bug! Caso alguma coordenada de p0 seja menor que a coordenada de p1, não vamos conseguir iterar de um ponto ao outro. Então precisamos checar se isso é verdade, e caso seja, precisamos fazer um swap!
OBS: swap é um termo usado para trocarmos o valor de duas variáveis entre sí.
Caso p0 > p1p0 = p1 e p1 = p0 e não vamos precisar alterar a lógica do nosso código. Vamos conseguir continuar usando os mesmos laços sem ter que fazer alguma iteração no sentido contrario.
function drawLine(p0, p1, color):
dx = abs(p1.x - p0.x)
dy = abs(p1.y - p0.y)
if dx > dy:
if p0.x > p1.x:
swap(p0, p1)
a = dy/dx
b = p0.y - a* p0.x
for x=p0.x; x<=p1.x; x++:
y = a*x + b
putPixel(x, y, color)
else:
if p0.y > p1.y:
swap(p0, p1)
// função linear "inversa"
a = dx/dy
b = p0.x - a* p0.y
for y=p0.y; y<=p1.y; y++:
x = a * y + b
putPixel(x, y, color)
Implementando o codigo!
Por fim temos nossa implementação do nosso algoritmo para desenhar linhas! Ainda podemos melhorar muito nosso algoritmo de linhas, existindo algoritmos mais poderosos para tal função como o algoritmo de Bresenham.
Mas para o nosso fim, este algoritmo é bom o suficiente. Caso deseja, pode implementar o algoritmo de Bresenham que não mudará em nada o progresso daqui em diante.
“Por vezes e vezes ele dividiu, e mediu
espaço por espaço em sua nove vezes escuridão,
o não visto, o não conhecido, as mudanças apareceram
como montanhas desoladas, racharam furiosas
pelos ventos escuros da pertubação”
tradução livre do primeiro capitulo do livro de Urizen de William Blake
Em algum momento imaginei que eventualmente citaria William Blake. E em particular um de seus personagens de sua cosmogonia pessoal: Urizen.
William Blake foi, se me permitem resumir seus feitos, um pintor e poeta inglês que viveu uma época de instabilidade religiosa na Inglaterra. Como os ingleses não seguiam os preceitos católicos vindos do Vaticano desde a rebelião de Henrique VIII o povo inglês era uma amalgama de vários grupos cristãos e cada grupo com a sua própria visão e valores do que era ser cristão.
Blake não era diferente dos demais ingleses. Tido por muitos como peculiar (talvez um eufemismo para o que alguns chamariam de loucura) ele afirmava que tinha visões e vislumbres de realidades mais sensíveis do que nós, indivíduos com menor capacidade visual/espiritual, apenas podemos conjecturar. Para nossa sorte Blake pintou e escreveu todas suas ideias e visões. E nesse processo criou sua própria cosmogonia e seu próprio panteão de personagens que prototipavam os arquétipos do ser humano, e por extensão, da realidade em sí.
Então voltamos ao homem da pintura acima. Ele é Urizen. Na cosmogonia de Blake é o lado racional do homem. Urizen, ou a razão, quando nasce e ve a sí própria, acredita que ela foi o motivo em sí mesma, e logo, não existe nada além dela. Então Urizen conclui que tudo ao seu redor deve nascer de sí.
Então caros amigos, criarmos um mundo tridimensional em um equipamento que usa apenas a lógica é onde exercemos a maior óde a Urizen possível. Aqui é onde estamos começando uma aventura em ideias de como simular a física de nosso mundo e até de compreender como a logica do próprio universo funciona para capturar essas ideias e representar em uma linguagem lógica que nossas maquinas de Turing consigam resolver e acender as cores certas na tela.
Do que você está falando ?
Neste texto nós vamos começar a representar figuras tridimensionais. Para isso vamos ter uma interpretação do espaço do mundo simulado e do espaço bidimensional da tela. E encontrar uma forma de identificar o que está na tela da câmera e, por fim, projetar o mundo tridimensional na tela.
Estas ideias são a base da computação gráfica. E os algoritmos podem suscitar ideias sobre a simulação da realidade, o quão longe podemos ir e quais as restrições. Então vamos colorir nossas ideias e saber o que em nós esta assumindo o controle quando estamos no papel de criar um universo em nossas próprias mãos. Um spoiler: na cosmogonia de Blake, Urizen não necessariamente é o bonzinho da história.
Então como vai funcionar ? Bom nós queremos ter objetos com três dimensões em um espaço tridimensional e queremos ter alguma forma de filma-los, ou seja, alguma forma de saber quais objetos e/ou quais partes desses objetos estão na nossa tela.
Então… vamos pensar em uma câmera. Imagine que teremos uma câmera onde o que ela captura na verdade vai ser nossa tela.
No post anterior nós chegamos na caneta de Urizen. Neste post vamos elaborar o esquadro e a régua.
Uma câmera funciona como o experimento da câmara escura. Em que a fotografia ou o video é capturado dentro da câmera.
Podemos reproduzir o experimento da câmera escura simplificado, onde o plano onde a luz vai ser projetada vai ser um plano conhecido, e esse plano vai ser a nossa tela.
A ideia para descobrir isso vai ser com um pouquinho de geometria. Mas o que queremos procurar é qual o ponto \(P'\) no plano de projeção para um ponto \(P\) no mundo. E vamos fazer essa pergunta para todos os pontos do mundo. Os pontos que estiverem dentro do intervalo da nossa tela \([-0.5, 0.5]\) em \(x\) e \([-0.5, 0.5]\) em \(y\). Dai com a nossa tela com vários pontos dos nossos polígonos tridimensionais, vai bastar fazer um mapeamento dos pontos tela->monitor que funcionaria como mapear \([-0.5, 0.5]=> [0, 1980] pixels\) para a largura e o mesmo para a altura. E com isso teremos o suficiente para projetar pontos tridimensionais para a nossa tela.
projetaObjetoTridimensional(objeto):
para cada objeto no mundo:
para cada ponto do objeto
projete o ponto no plano
desenhe linhas entre os pontos projetados
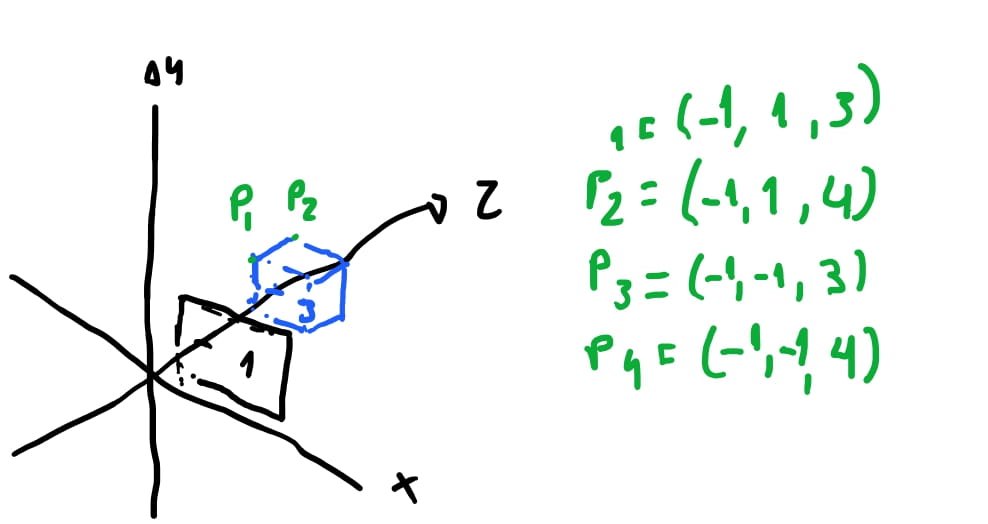
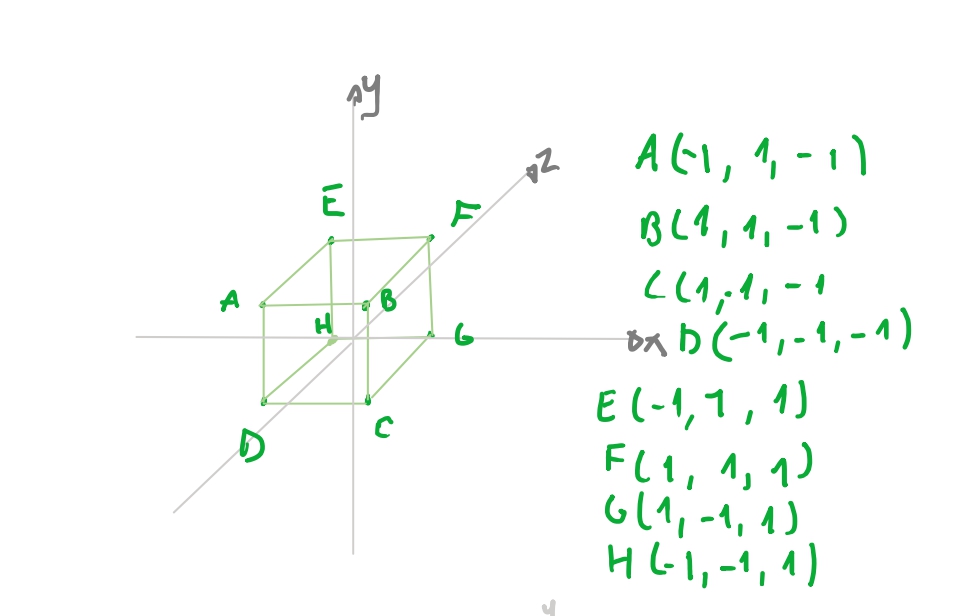
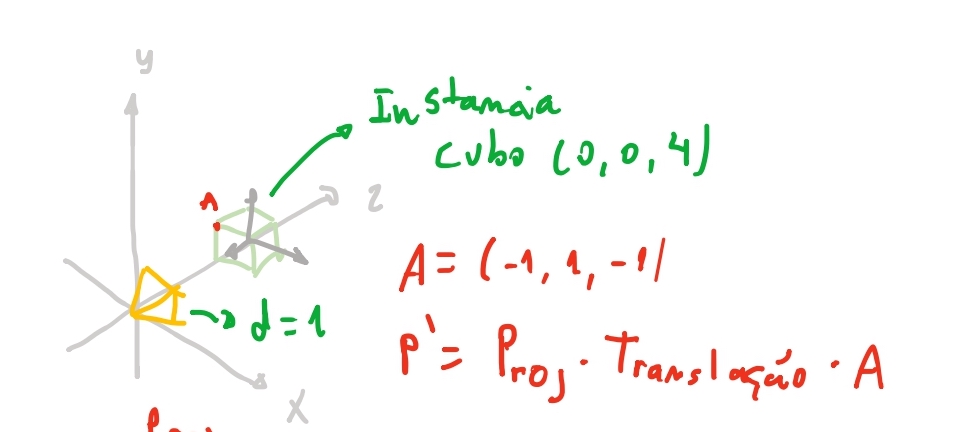
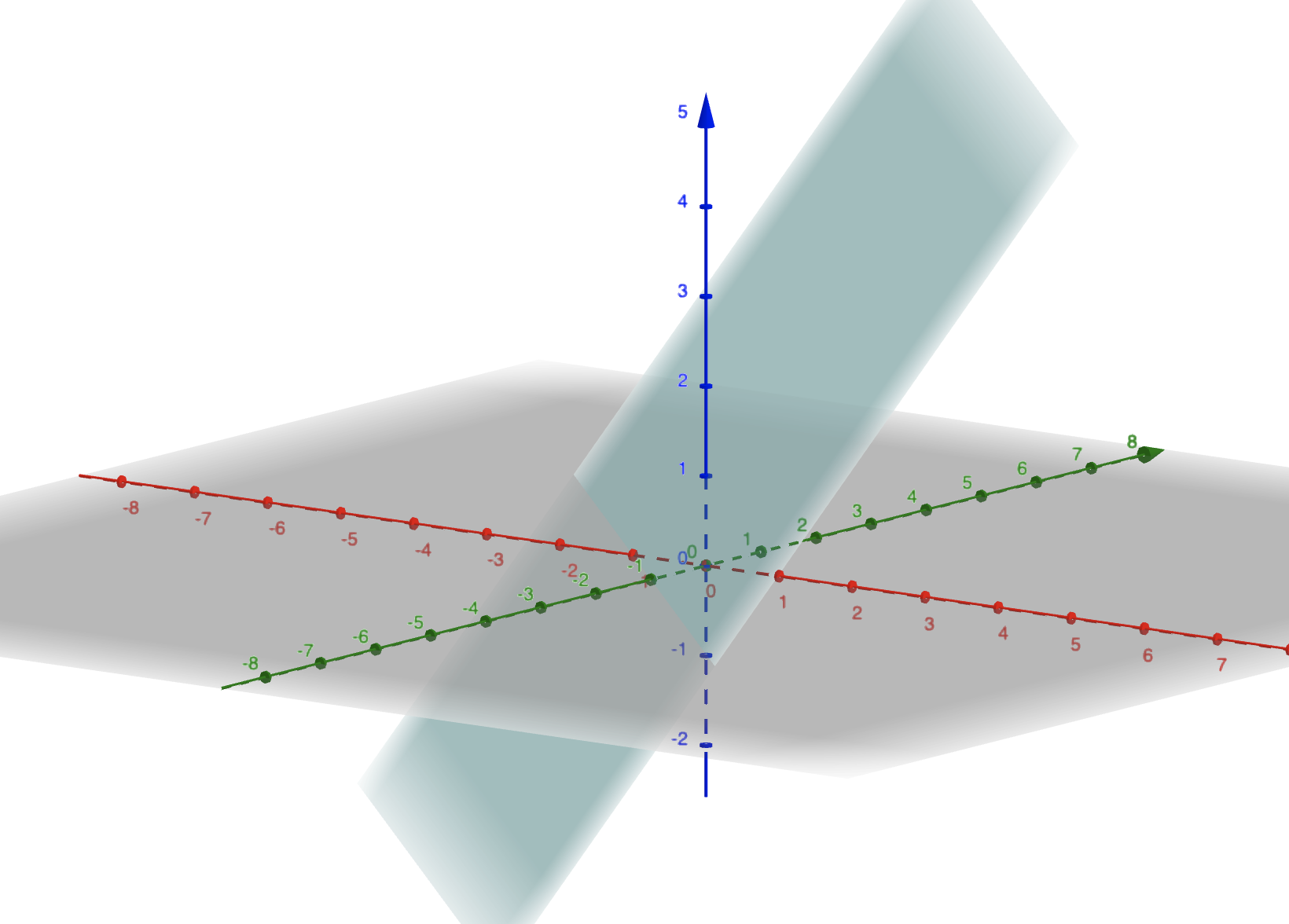
Vamos usar a cena acima: temos um cubo na cena, e temos um plano centralizado em \(z_+\), e a uma distancia \(d = 1\).
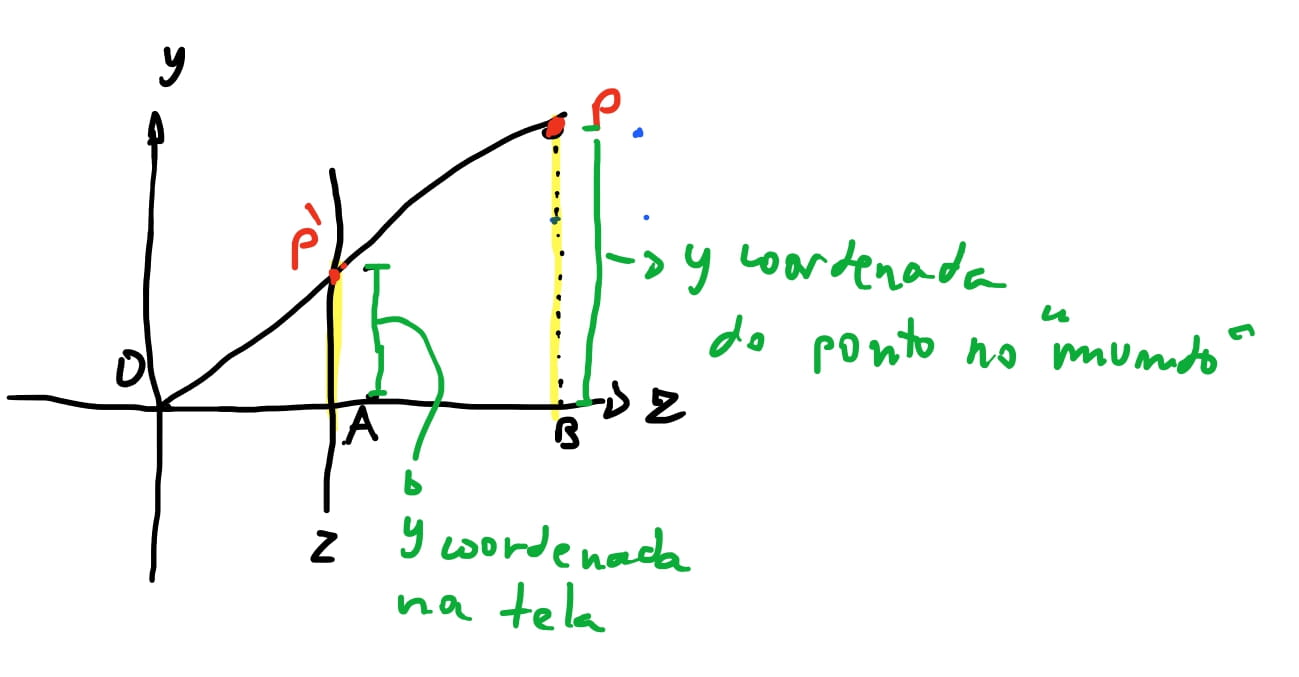
Então vamos pensar como podemos obter \(P'\). Se olhar-mos a nossa cena de forma que o eixo \(y\) fique pra cima e o eixo \(z\) para a direita e o \(x\) na nossa direção, vemos que foma um triangulo com a reta que liga a origem \(O(0,0,0)\) cruzando o nosso plano de projeção \(proj\).
🤔 se queremos calcular o ponto \(P'\), podemos ver que o valor da sua \(y\)-coordenada é o segmento \(\overline{P'A}\)(para ser mais correto: é o valor do segmento \(\overline{P'A}\) projetado no eixo \(y\)).Sabemos também que o valor da sua \(z\)-coordenada é a mesma da distancia plano \(proj\) da origem.
Se usarmos a proporção do triangulo de que \(\frac{\overline{P'A}}{\overline{OA}} = \frac{\overline{PB}}{\overline{OB}}\) então podemos chegar que \(\overline{P'A} = \frac{\overline{OA} * \overline{PB}}{OP}\).
E sabemos todos os valores que vamos precisar nessa equação: \(\overline{PB}\) é o valor da \(y\)-coordenada do ponto \(P\). O valor \(\overline{OA}\) é a distancia do plano de projeção da nossa origem no eixo \(z\), portanto, \(d\). E por fim o valor de \(\overline{OB}\) é a \(z\)-coordenada do ponto \(P\). Então temos:
Para o eixo \(x\) vamos ter a reciproca! Só que dessa vez vamos olhar como se olhássemos a nossa cena de cima. Com o eixo \(z\) para cima, o eixo \(x\) para os lados e o eixo \(y\) como se tivesse apontado para nós.
Chegamos em uma equação bem similar, porem considerando a \(x\) coordenada. Agora sabemos encontrar a posição de um ponto qualquer no mundo projetado no nosso plano de projeção. Vamos testar para ver se acontece como planejado!
Vamos supor que nosso plano de projeção esteja a uma distancia de \(d = 1\) do eixo \(z\). Isto é, imagine que o centro do plano esteja em \(proj = (0,0,1)\). E imagine que temos um cubo que tenha os oito pontos à duas unidades na frente do nosso plano e tenha alguns dos pontos: \(P_1(-1, 1, 3)\),\(P_2(-1, 1, 4)\), \(P_3(-1, -1, 3)\), \(P_4(-1, -1, 4)\), \(...\).
Se acompanhar as contas acima e desenhar os pontos que encontramos, os pontos que estiverem dentro do intervalo de nosso plano de projeção \([-0.5, 0.5]\) vão ser desenhados. E podemos conferir, como desenhamos à esquerda, que nosso algoritmo funciona! Podemos conferir que \(P_1(-1, 1, 3) => (-0.3, 0.3, 1)\).
Uma percepção da nossa visão é que realmente quanto mais longe as coisas estão de nós, menor elas parecem ficar. Então faz sentido os nossos cálculos dividir por \(z\) ou seja a distancia da origem que o objeto está do observador, menor parece ficar … o tamanho aparente é inversamente proporcional à distancia do observador 😅.
hora de implementar !
Então agora que temos as equações nas mãos e vemos que funciona, é hora de transformar em código. Então o que queremos fazer é descrever a nossa cena, colocando onde está nosso plano de projeção, e o nosso cubo. Vamos então mapear os pontos da nossa cena, para as coordenadas do plano. Com essas coordenadas no nosso plano, vamos mapear elas para os pixels da tela e por fim, desenhar as linhas entre cada ponto.
Devemos perceber então que as linhas são desenhadas na tela, e não no “plano de projeção”.
Com essas funções e os vértices do cubo, agora basta que liguemos cada cubo, desenhando as arestas dos cubos chamando a função de desenhar_linha que vimos no post anterior.
Então vamos ligar cada aresta manualmente:
constcanvas=document.getElementById("canvas");constcontext=canvas.getContext("2d");constwidth=canvas.width;constheight=canvas.height;constcanvasBuffer=context.getImageData(0,0,width,height);constblit=()=>{context.putImageData(canvasBuffer,0,0);};constcanvasPixel=(x,y,r,g,b,a)=>{x=Math.floor(x);y=Math.floor(y);constindex=(x+y*width)*4;canvasBuffer.data[index+0]=r;canvasBuffer.data[index+1]=g;canvasBuffer.data[index+2]=b;canvasBuffer.data[index+3]=a;};constputPixel=(x,y,color)=>{letcanvasX=width/2+x;letcanvasY=height/2-y;canvasPixel(canvasX,canvasY,color.r,color.g,color.b,color.a);};constdrawLine=(p0,p1,color)=>{letdx=p1.x-p0.x;letdy=p1.y-p0.y;if(Math.abs(dx)>Math.abs(dy)){if(p0.x>p1.x){letcopy=p1;p1=p0;p0=copy;}consta=dy/dx;letb=p0.y-a*p0.x;for(letx=p0.x;x<p1.x;x++){lety=a*x+b;putPixel(x,y,color);}}else{if(p0.y>p1.y){letcopy=p1;p1=p0;p0=copy;}consta=dx/dy;constb=p0.x-a*p0.y;for(lety=p0.y;y<p1.y;y++){letx=a*y+b;putPixel(x,y,color);// x = x + a;}}};constRED={r:255,g:0,b:0,a:255};constBLUE={r:0,g:0,b:255,a:255};constGREEN={r:0,g:255,b:0,a:255};letvP1={x:-1,y:1,z:3}letvP2={x:1,y:1,z:3}letvP3={x:-1,y:-1,z:3}letvP4={x:1,y:-1,z:3}letvP5={x:-1,y:1,z:4}letvP6={x:1,y:1,z:4}letvP7={x:-1,y:-1,z:4}letvP8={x:1,y:-1,z:4}constPLANE_DISTANCE=1;letprojectVertex=(vertex)=>{return{x:(vertex.x*PLANE_DISTANCE)/vertex.z,y:(vertex.y*PLANE_DISTANCE)/vertex.z,z:vertex.z}}constPLANE_WIDTH=1;constPLANE_HEIGHT=1;constviewPortToCanvas=({x,y,z})=>{return{x:x*(width/PLANE_WIDTH),y:y*(height/PLANE_HEIGHT)}}drawLine(viewPortToCanvas(projectVertex(vP1)),viewPortToCanvas(projectVertex(vP2)),RED)drawLine(viewPortToCanvas(projectVertex(vP2)),viewPortToCanvas(projectVertex(vP3)),RED)drawLine(viewPortToCanvas(projectVertex(vP3)),viewPortToCanvas(projectVertex(vP4)),RED)drawLine(viewPortToCanvas(projectVertex(vP4)),viewPortToCanvas(projectVertex(vP1)),RED)drawLine(viewPortToCanvas(projectVertex(vP5)),viewPortToCanvas(projectVertex(vP6)),GREEN)drawLine(viewPortToCanvas(projectVertex(vP6)),viewPortToCanvas(projectVertex(vP7)),GREEN)drawLine(viewPortToCanvas(projectVertex(vP7)),viewPortToCanvas(projectVertex(vP8)),GREEN)drawLine(viewPortToCanvas(projectVertex(vP8)),viewPortToCanvas(projectVertex(vP4)),GREEN)drawLine(viewPortToCanvas(projectVertex(vP1)),viewPortToCanvas(projectVertex(vP5)),BLUE)drawLine(viewPortToCanvas(projectVertex(vP2)),viewPortToCanvas(projectVertex(vP6)),BLUE)drawLine(viewPortToCanvas(projectVertex(vP3)),viewPortToCanvas(projectVertex(vP7)),BLUE)drawLine(viewPortToCanvas(projectVertex(vP4)),viewPortToCanvas(projectVertex(vP8)),BLUE)blit();
o que escondemos ?
Acabamos não falando de angulo de visão ou porque desenhamos as linhas em alguma ordem específica. O tamanho e a posição do plano vai dizer qual angulo de visão a câmera terá.Até agora apenas esbarramos na superfície da computação gráfica, mas já temos uma boa ideia de como a matemática da projeção funciona. E isso vai nos dar alguma liberdade para nos próximos textos pensarmos apenas como podemos estender este exemplo para gráficos mais abrangentes. Vamos falar de como podemos criar objetos tridimensionais quaisquer e movimenta-los pelo mundo tridimensional.
Agora que temos ambos esquadro e caneta, Urizen vai poder criar seu mundo de razão. Nos poemas de Blake, Urizen, ou a razão humana, vagueia por ai dando nomes e dividindo as coisas para entende-las. E esse é apenas o nosso começo do poema. Em um ponto do poema, Urizen se encontra acorrentado pelas correntes de Los, o principio criativo da mente humana. Somente então Los cria uma imagem humana de Urizen, e a união perfeita do homem com a sua Razão (Urizen) e sua Imaginação (Los) cria o homem perfeito Albion. Até chegar-mos ao fim de um rasterizador completo e finalmente Urizen ver a si isolado no seu próprio mundo vazio e acorrentado pela própria criação é que daremos espaço para Los nascer e conseguiremos deixar com que a nossa criatividade embelezar nosso mundo tridimensional de árvores, arte e musica. Mas não se deixem enganar: ainda é um mundo artificial de Urizen!
O seculo XX foi marcado de várias mudanças sociais, cientificas e estruturais pro mundo inteiro. Impérios deixaram de existir para dar berço as sociedades democráticas, o mundo deixou de girar em torno da Inglaterra, a ciência deixou de ser absoluta para ser relativa, a arte questionou a sí mesma e “o que é arte?”. Um dos grandes eventos do seculo XX foi a segunda guerra mundial e os seus impactos. Na tentativa de quebrar a criptografia alemã, um jovem matemático de nome Alan Turing, usou a sua teoria de computabilidade para tentar chegar em uma quebra na criptografia das comunicações alemãs. Ele havia desenvolvido essa teoria para tentar responder uma das cinco perguntas elaboradas pelo matemático David Hilbert. Essas perguntas tinham a finalidade de encontrar, de forma definitiva, formalizar a matemática. Uma das cinco perguntas de Hilbert era “existe um algoritmo capaz de decidir se qualquer declaração matemática é verdadeira ou falsa”. Turing então elaborou “como definir” um algoritmo e como computa-lo e provou que tal algoritmo de decidir qualquer declaração como verdadeira ou falsa não deve existir. E então essa teoria de maquinas foi dada o seu nome conhecidas hoje com “Maquinas de Turing”, e são a base da computação moderna.
Ao fim da segunda guerra mundial, a URSS começou seu próprio programa nuclear, assim como os Estados Unidos importou algumas mentes por trás dos foguetes V2 que eram usados para bombardear a Inglaterra. E a guerra fria começa: com o pretexto de conquistas espaciais, era o plano de fundo para uma guerra que acontecia apenas no campo mental: Uma guerra tecnológica pela influencia politica sobre o mundo. Quem conseguisse dominar a tecnologia dos foguetes intercontinentais estaria em grande vantagem cientifica sobre o outro. Esta vantagem seria tão absurda que permitiria uma constante vigilância do globo. Então as duas superpotências corriam para desenvolver os melhores foguetes possíveis. E para demonstrar a superioridade tecnológica estavam fazendo feitos espaciais de demonstração de força. Quem conseguisse colocar um satélite implicava na habilidade de sondar qualquer parte do globo: e isso era claro no medo dos estado unidenses acreditando que o Sputnik, o primeiro satélite em orbita, estivesse sondando ou atacando os americanos com ondas radioativas.
Mas a ideia era clara: o objetivo de ambos era conseguir acertar “precisamente” um alvo em qualquer lugar do mundo com um ogiva nuclear. A corrida espacial, portanto, não passou de um pano de fundo pra uma corrida armamentista de misseis balísticos transcontinentais. E as Maquinas de Turing foram essenciais novamente nesse conflito. O que antes foi usado para terminar uma guerra, agora estava sendo usado para guiar os misseis.
Então o programador completamente versado no idioma das maquinas tem o poder de decidir se é quem guia os foguetes ou quem termina guerras.
Nestes últimos conjuntos de textos estamos criando um mundo tridimensional na mesma Maquina de Turing. Aqui estamos escolhendo então como criar ao invés de destruir. E neste vamos fazer nossa Maquina de Turing a entender o que são as três dimensões, e para isso, vamos precisar de algumas ferramentas matemáticas. Vamos precisar declarar para nossa maquina como ela pode “entender” o que são as três dimensões, o que é um ponto, como saber onde este ponto está no espaço e como podemos mover estes pontos no espaço. E por fim, como podemos “projetar” esse espaço tridimensional da memoria do computador para a tela para que podemos “ver” o nosso mundo digital.
No post anterior vimos como desenhar um objeto tridimensional com perspectiva, dada uma representação de uma figura tridimensional. Apresentamos apenas a matemática por trás da ideia. Para irmos além aquele método apresenta alguns problemas:
Não conseguimos desenhar qualquer objeto tridimensional com o método, por exemplo, esferas. Pois o algoritmo depende de decompor em linhas
Toda vez que fossemos criar um objeto em cena, precisaríamos dizer qual a ordem dos desenhos de cada aresta. E não só isso: A câmera precisa ficar estacionada em \((0,0,0)\).
Se fossemos criar outro cubo, repetiríamos todo o cubo, porem, movendo cada aresta 😩
Então pensando nestes problemas vamos criar uma forma melhor de descrever os objetos tridimensionais e como podemos criar abstrações para desenha-los na tela.
Descrevendo a cena tridimensional
Ok, vamos bolar algum jeito de resolver os problemas citados.
Vamos começar em: como podemos desenhar qualquer figura tridimensional usando a nossa técnica de projeção.
No exemplo anterior para desenhar um cubo nós desenhamos aresta por aresta. Isso é um pouco limitante porque teríamos que saber como reduzir todas as figuras em retas.
Para contornar isso, e automatizar nosso algoritmo para desenharmos qualquer coisa com a mesma equação de projeção que chegamos anteriormente, podemos pensar em reduzir todas as formas em figuras mais simples!
Então e se reduzirmos tudo à triângulos? Triângulos são simples de representar e desenhar. São os polígonos mais simples e todos os pontos estão sempre no mesmo plano! Aqui tem um ótima descrição do porque triângulos são excelentes polígonos para reduzir qualquer figura tridimensional. Infelizmente o video é em inglês.
Se decompormos nossas figuras em triângulos precisamos apenas saber quais sao os pontos e como ligar os pontos. No nosso cubo teríamos na face \(ABCD\) os triângulos: \(ABD\) e \(BCD\). Podemos então fazer a seguinte ideia:
triangulo:
| tupla( vertice1, vertice2, vertice3)
modelo:
| vertices: lista ( tupla (x, y, z))
| faces: lista( triangulo )
E então para desenhar qualquer figura descrita dessa forma teríamos :
função desenha_objeto(objeto)
para cada face em faces(objeto):
para cada triangulo em face:
desenha_triangulo(triangulo)
função desenha_triangulo(triangulo):
// linha p1-p2
desenhe_linha(
projeção->tela(
mundo->projeção(vértice1)
),
projeção->tela(
mundo->projeção(vértice2)
),
)
// linha p2-p3
desenhe_linha(
projeção->tela(
mundo->projeção(vértice2)
),
projeção->tela(
mundo->projeção(vértice3)
),
)
// linha p3-p1
desenhe_linha(
projeção->tela(
mundo->projeção(vértice3)
),
projeção->tela(
mundo->projeção(vértice1)
),
)
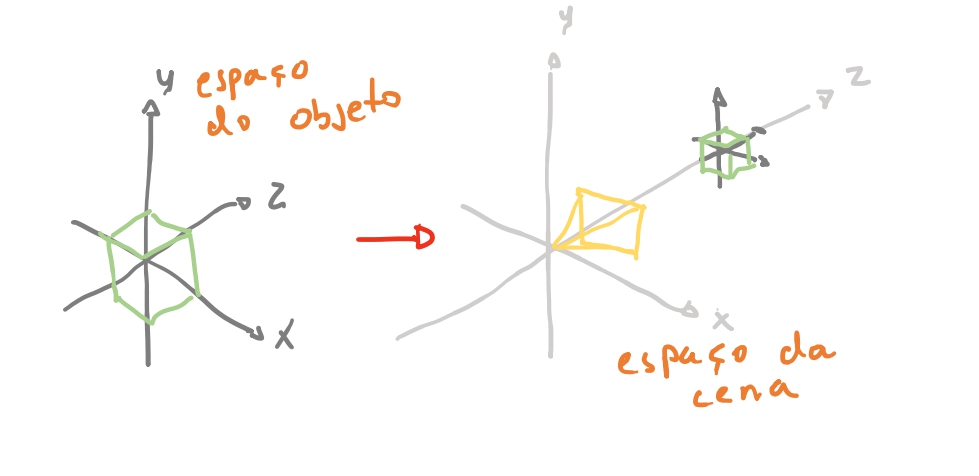
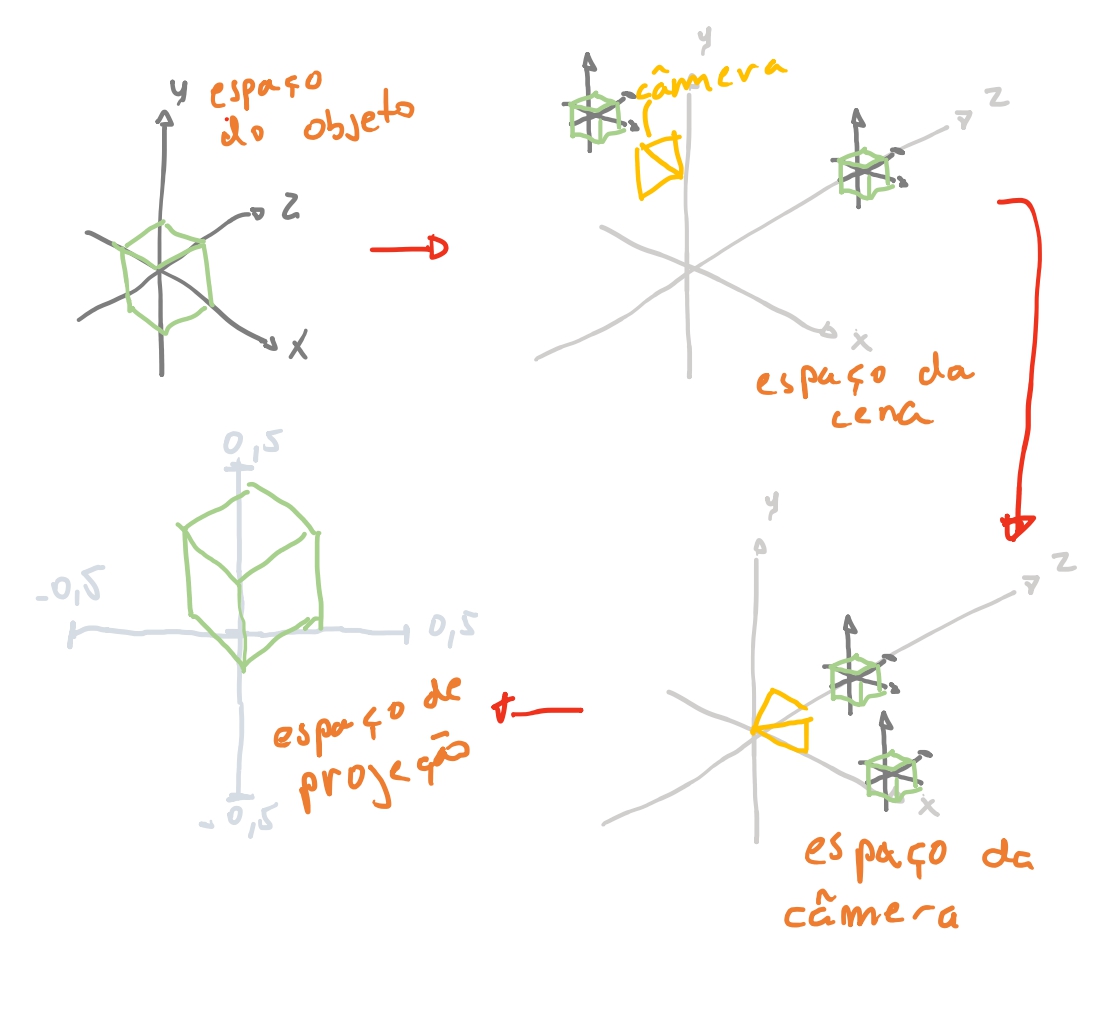
O cubo foi definido seus vértices em relação a origem. Vamos chamar esse eixo \(x y z\) de o espaço do cubo. Nesse espaço tem apenas todos os vértices do cubo.
Agora imagine que temos o eixo \(x y z\) da nossa cena. E nela imagine que temos um cubo a uma distancia de \(4\) unidades da nossa câmera, no eixo \(z\).
Dizemos que este espaço é o espaço da cena. Mas como vamos levar as coordenadas do nosso cubo para as coordenadas do mundo? 🤔
Se a nossa câmera está na origem \((0,0,0)\), o nosso cubo está em \((0,0,4)\). Então no nosso espaço da cena só precisamos levar os vértices do nosso cubo para essa posição. Se nós somar-mos todas as coordenadas do nosso cubo \((-1, 1, -1) + (0, 0, 4) = (-1, 1, 3) ...\) teremos todos os nossos vértices do cubo movidos para a coordenada do espaço da cena.
Vamos usar essa ideia para iniciar nossa modelagem! Queremos então separar um modelo de objeto de sua instancia. Vamos chamar de instancia o que estiver na nossa cena. E modelo o objeto com seus pontos em seu espaço de objeto. Podemos chegar na seguinte ideia:
Então nessa nossa descrição atual o que faríamos seria a nossa instancia, teria uma posicao_cena = (0, 0, 4) que somaria em todos os vértices do modelo do cubo a posição em cena. Dessa forma conseguimos ter quantas instancias de cubos quisermos e na posição que quisermos.
Mas… 🤔 como podemos girar, escalar? Vamos precisar de transformações.
Entendendo transformações
Esta parte do texto é onde eu vou explicar como vamos fazer para transformar a posição dos objetos em cena. Vai ser uma introdução alguns conceitos matemáticos de uma area chamada “álgebra linear”. Se quiser, pode só pular este capitulo e seguir para o próximo, onde vamos apenas usar essas estruturas 🤷. Apesar de poder ignorar e só usar “como funciona” é possível mas vai ser difícil de entender como tudo funciona.
Vamos começar explicando como as transformações em 2D funcionam. Assim que entendemos elas, vamos aumentar para trés dimensões!
Um conceito inicial são vetores. Vetores em duas dimensões são as coordenadas \((x, y)\) de um ponto no plano. O ponto \((2, 2)\) é o vetor \(\vec{v} = (2, 2)\) em que sua \(x\)-coordenada\(=2\) e sua \(y\)-coordenada\(=2\).
A soma e a subtração de vetores é a soma de suas coordenadas. Então a soma de \(\vec{v} + (1,2) = (3, 4)\).
Multiplicar um vetor por um numero é multiplicar as componentes vetor \(\vec{v} = (2, 2)\cdot3 = (6,6)\). Chamamos o numero multiplicado de escalar. E realmente passa a ideai de “esticar” o vetor em uma multiplicação por um valor \(>1\) e de “encolher” caso multiplicamos por \(< 1\).
Multiplicar dois vetores é um pouco mais complicado. Então vamos abordar no futuro.
Então temos cada vértice o nosso cubo é dado por um vetor. Queremos então encontrar uma forma de rotacionar os pontos do cubo (nossos vetores), esticá-los e, por fim, move-los.
Vamos começar com “estica-los”. Como vimos acima, para “escalar” um vetor, basta multiplicar pelo valor de escala. Poderíamos então com a nossa instancia, “multiplicar” todos os vértices por um valor de escala. E para mover bastaria somar com o vetor de posição do nosso cubo. O problema começa a aparecer ai. Seriam muitas contas que teríamos que deixar explicitas e nosso código começaria a ficar muito complexo e difícil de acompanhar.
E se pudéssemos fazer algo como: se temos um vértice \(V\) \(V' = T_{ranslacao} \cdot R_{otacao} \cdot E_{scala} \cdot V\) e \(V'\) seria o vetor que queríamos? Poderíamos usar as mesmas operações em todos os vértices!
everything is a matrix neo
Então finalmente chegamos na citação do Morpheus no filme matria. Felizmente, existem essas ferramentas na matemática : matrizes.
OBS: Aqui temos um link para caso você não seja familiar com o básico das operações em matrizes ou precise revisar!
Podemos representar um vetor bidimensional como uma matriz \(2 \times 1\), ou seja, nosso vetor \(\vec{v} = \begin{bmatrix} 2 \\ 2 \end{bmatrix}\). E então se multiplicarmos uma matriz pelo nosso vetor, vamos transformar nosso vetor! Mas lembrando de algumas propriedades básicas de matrizes: se quisermos obter um vetor de volta, ou seja, uma matriz de forma \(2 \times 1\), teremos que multiplicar por uma matriz \(2 \times 2\).
Então vamos ver como podemos chegar em uma matriz de “escala”:
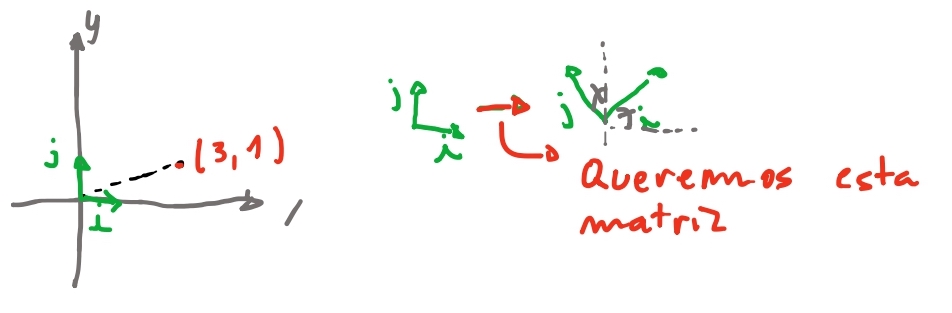
Na imagem acima colocamos nosso vetor \(\begin{bmatrix} 2 \\ 2 \end{bmatrix} \times \begin{bmatrix} i & j \end{bmatrix}\) , o que isso significa 🤔?
Pra entender a imagem acima pensem que os eixos também são vetores:
E então os eixos são múltiplos de ambos os vetores \(\vec{i}\) e \(\vec{j}\).
Agora vem a magia das matrizes: As transformações nos vetores multiplicados pela matriz vão ser “como \(\vec{i}\) e \(\vec{j}\) se transformam”.
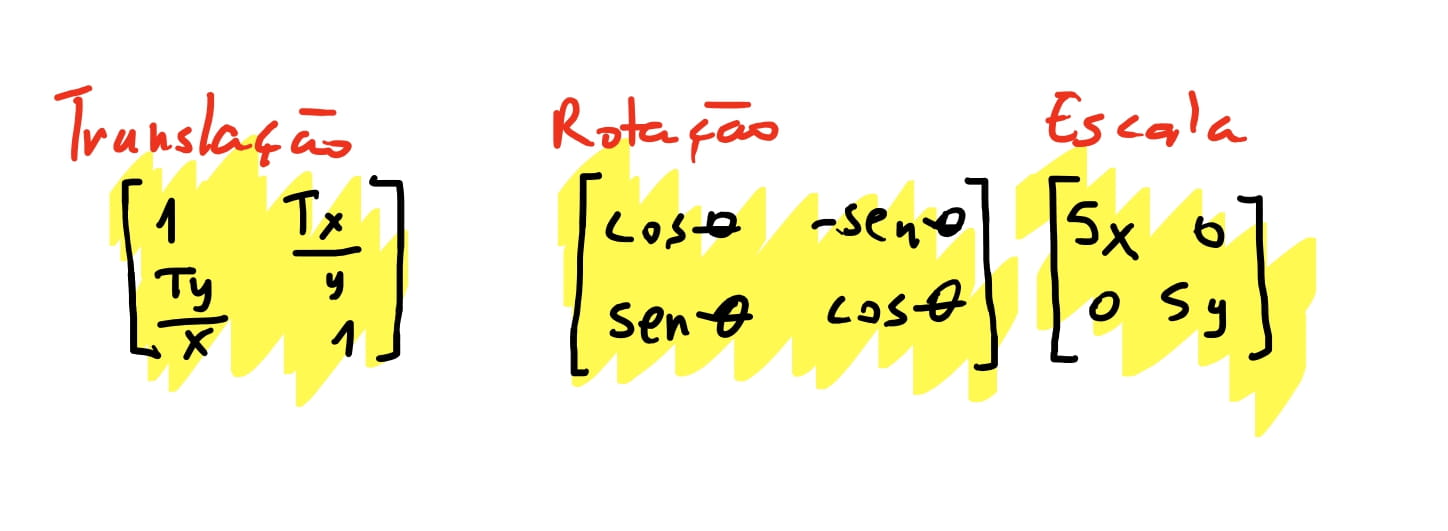
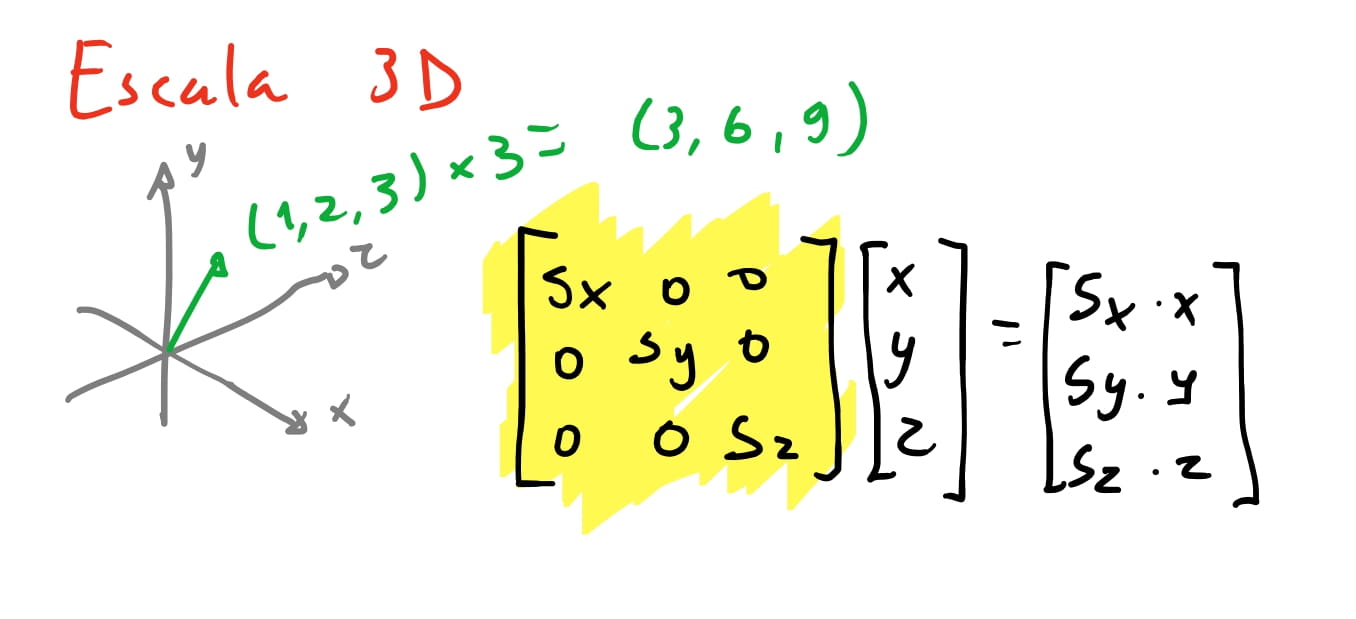
No exemplo anterior, chegamos em que a matriz para escalar um vetor é \(\begin{bmatrix} x & 0 \\ 0 & x\end{bmatrix}\). Em outras palavras é a matriz em que pegamos \(i = (1, 0) \cdot x\) e \(j = (0, 1) \cdot x\) e \(x\) é o nosso valor de escala! Quando multiplicamos o nosso vetor por essa matriz, nosso vetor escala igualmente os vetores \(\vec{i}\) e \(\vec{j}\)! 😮💨
Com tudo isso dito vamos ver como podemos rotacionar um vetor.
Para rotacionar um vetor \(\vec{v}\), queremos então rotacionar os vetores \(\vec{i}\) e \(\vec{j}\). Como eles são os nossos eixos queremos manter que eles continuem perpendiculares entre si. Então queremos rotacionar os dois a mesma quantia.
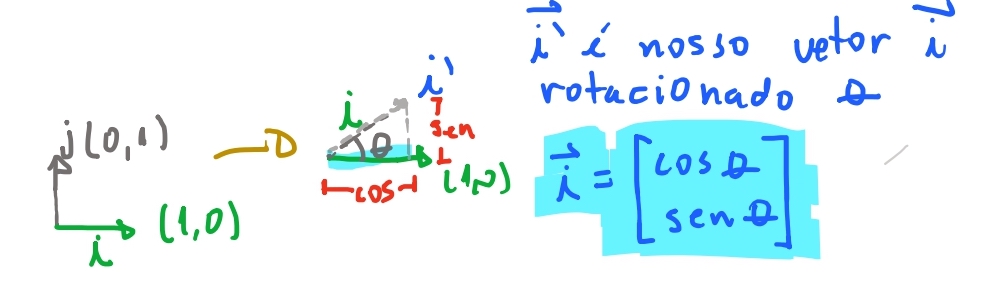
Vamos começar pensando como rotacionar o vetor \(\vec{i}\). E então rotacionaremos o vetor \(\vec{j}\).
Se quisermos rotacionar \(\vec{i}\) uma quantia \(\theta\), podemos usar trigonometria para saber a sua posição. Sabemos que o seu comprimento não muda. E pelas propriedades de trigonometria sua posição em \(y\) vai ser o \(\sin \theta\), pois a hipotenusa é o comprimento do nosso vetor (que não mudou de valor \(= 1\)). E o valor em \(x\) será o \(\cos \theta\) pela mesma razão.
Então o nosso vetor \(\vec{i}\) dada uma rotação \(\theta\), irá terminar em \((\cos \theta, \sin \theta)\). Ou em notação de matriz: \(\begin{bmatrix} \cos \theta \\ \sin \theta \end{bmatrix}\).
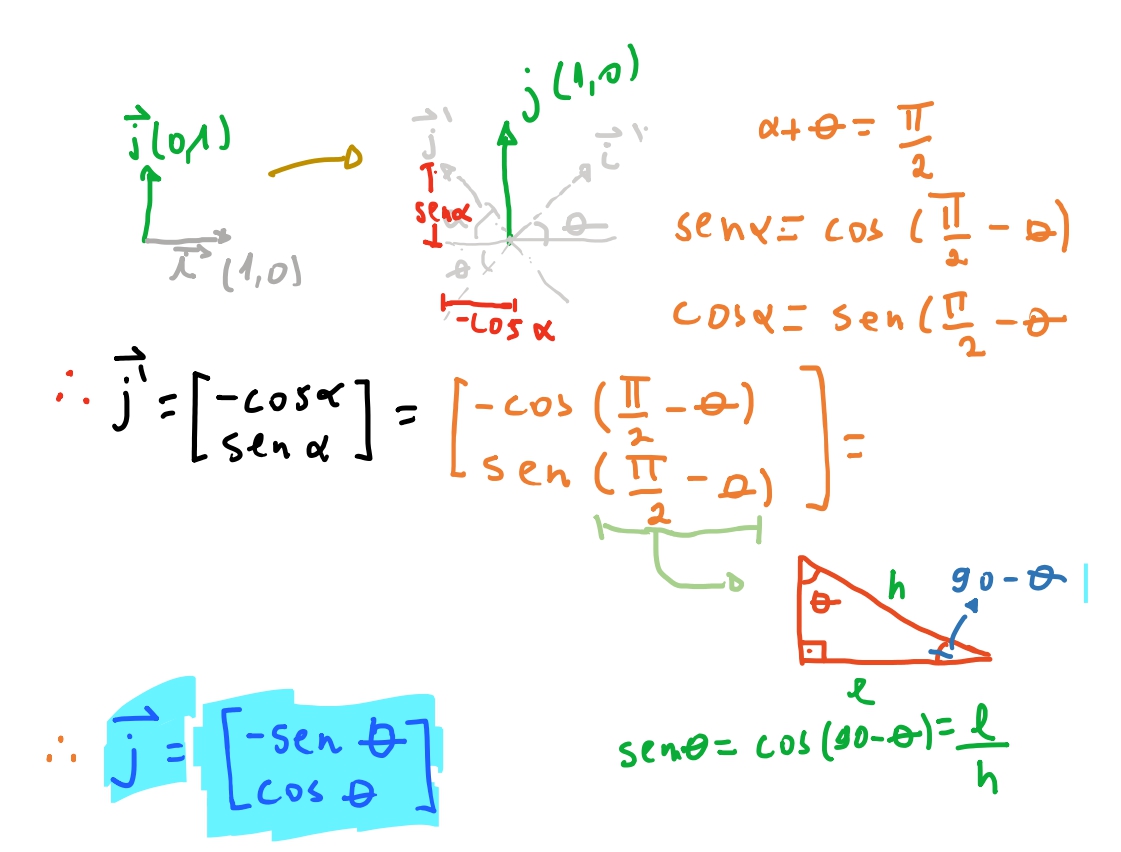
Para rotacionar o vetor \(j\) temos que usar um pouquinho mais de geometria. Pois \(\theta\) é o angulo entre \(i\) e \(i'\). Queremos então qual o angulo \(\alpha\) que o vetor \(j\) e onde \(j\) formam com o eixo horizontal apos a rotação. Sabemos que \(i\) e \(j\) são complementares, isto é, juntos somam \(90º\). Então sabemos que \(\alpha + \theta = \frac{\pi}{2} = 90º\). Então rotacionamos \(j\) por \(\alpha\) vamos ter \(j' = (-\cos \alpha, \sin \alpha)\), pelas mesmas propriedades trigonométricas que vimos para o vetor \(i\). Mas queremos esse vetor em relação ao angulo \(\theta\). Temos que \(\alpha = \frac{\pi}{2} - \theta\) e sabemos que: \(\sin\) de um angulo é igual ao \(\cos\) de seu complementar. Por fim então temos: \(\begin{bmatrix} -\sin \theta \\ \cos \theta \end{bmatrix}\) como a matriz para o vetor \(j\).
Com isso temos finalmente a matriz de rotação bidimensional : \(\begin{bmatrix} \cos \theta & -\sin \theta \\ \sin \theta & \cos \theta \end{bmatrix}\).
Vamos ver se conseguimos rotacionar um vetor \((3,1)\) \(30º\) em relação ao eixo horizontal.
Por fim vamos ver como podemos chegar em uma matriz para mover um vetor. É só pensar que queremos uma matriz \(\begin{bmatrix}A & B \\ C & D \end{bmatrix}\) que quando multiplicamos por um vetor \(\vec{v}\), essa matriz some em \(\vec{v}\) alguma quantia em \(vec{v} = (x+T_x, y+T_y)\). Então se fizermos esse produto, vamos chegar em um sistema de equações. Vamos ver como uma dessas equações do sistema vai ficar: \(Ax + By = T_x + x\). Como precisamos de \(x\), logo \(A\) pode ser \(1\), portanto \(By = T_x\).
Então disso temos que o valor \(B = \frac{T_x}{y}\). E similarmente, temos que \(C = \frac{T_y}{x}\). Então nossa matriz de translado é \(= \begin{bmatrix} 1 & \frac{T_x}{y} \\ \frac{T_y}{x} & 1 \end{bmatrix}\).
Então finalmente temos que as nossas matrizes de transformação para vetores bidimensionais são as seguintes:
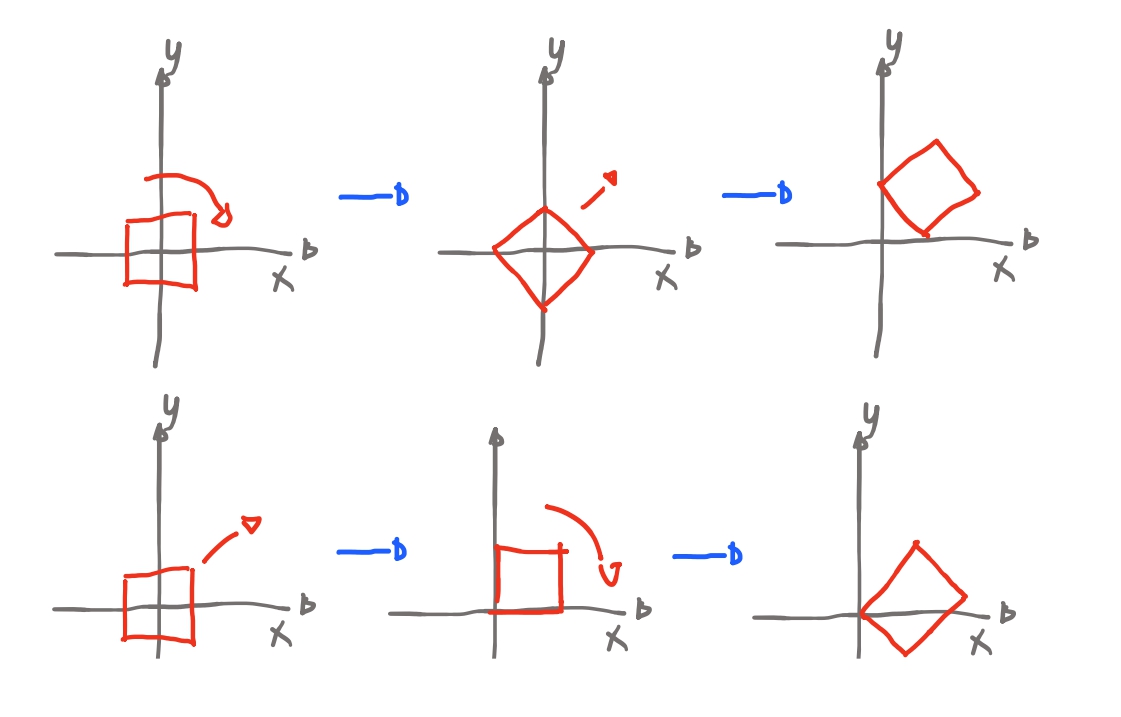
😮💨 Depois de tanta coisa temos que pensar “sera que a ordem dessas transformações importa”? E a resposta é: sim!
Veja, se rotacionamos um quadrado na origem, e depois o movemos é diferente de movermos um quadrado e depois rotacionamos:
Então pensando que vamos girar algo sempre em relação à origem, portanto é melhor começarmos escalando ja que não altera os pontos, apenas “os estica”. Depois podemos então rotacionar e por fim, mover. Se sempre usar-mos essa ordem, sempre as transformações serão como a gente espera : escalar -> rotacao -> mover.
Com tudo isso dito esta na hora de voltarmos para as três dimensões!
Estendendo para três dimensões
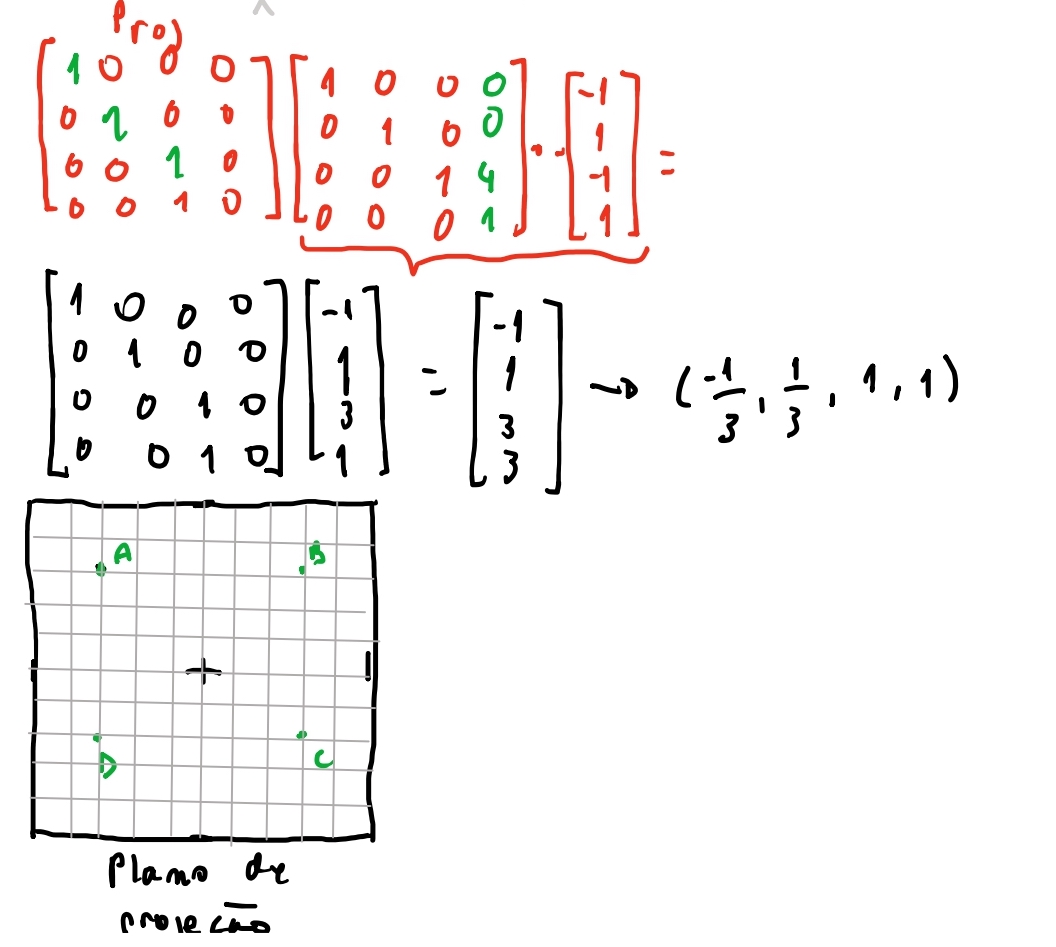
Então temos o nosso cubo no espaço do objeto. Temos a sua instancia que agora possui uma propriedade que nos diz sua rotação, escala e posição na instancia desse cubo no espaço de cena. Então relembrando o que queremos fazer é: pegar os vértices do nosso cubo, leva-los para o espaço de cena, projetar os vértices em cena no plano da câmera e por fim com os pontos da câmera, conectar os pontos como triângulos e desenha-los na tela. E agora temos matrizes para representar todas essas transformações da seguinte forma: para um vértice \(V\) do cubo, o ponto \(P'\) projetado vai ser: \(P'= P_{rojeção} \cdot T_{ransladar} \cdot R_{otacionar} \cdot E_{scalar} \cdot V\). Sendo que a matriz de \(P_{rojeção}\) a matriz que leva o ponto da cena para o espaço de projeção! E obter a nossa matriz de projeção é bem fácil depois de entendermos como funciona para projetar um ponto como vimos no post anterior.
um problema emerge 😨
O problema é que se tentar-mos usar a matriz de translação como fizemos vai acontecer um erro!
Vejamos:
Vamos testar nossas matrizes multiplicando juntas. Vamos testar rotacionar um vetor e transladar ele. Temos o vetor \((2,2)\) e queremos rotacionar por \(\frac{\pi}{4} = 45º\) e depois move-lo para a posição \((1, 3)\). Ele deveria então ir para a posição \((1, 5.82)\). Mas usando nossas matrizes ele não vai pro lugar certo! 😫
E ele não funcionou porque a matriz de translação que chegamos, só consegue transladar o vetor em que ela foi construída. No caso, a matriz \(\begin{bmatrix} 1 & \frac{1}{2} \\ \frac{3}{2} & 1 \end{bmatrix}\) só consegue transladar corretamente o vetor \((2, 2)\). Mas se multiplicarmos essa matriz por qualquer outro vetor, ela não mais vai fazer o que nós esperávamos. Então não vamos conseguir usar essa matriz de translado multiplicando as transformações. 🤔 E agora?
coordenadas homogêneas !
Um pequeno truque vai permitir que nós possamos fazer a nossa matriz de translado conseguir multiplicar o translado a todas as outras transformações: e esse truque chama coordenadas homogêneas. A ideia é colocar mais uma coluna em todas as transformações e usar o nosso vetor de duas dimensões com \((z = 1)\), ou seja, \((2, 2, 1)\).
Dessa forma, se estendermos todas as transformações, poderemos multiplicar as transformações como pensamos!
Agora finalmente podemos estender nosso exemplo bidimensional para a terceira dimensão! E da mesma forma vamos usar coordenadas homogêneas nas transformações tridimensionais. Então um vetor tridimensional \((x,y,z)\) vamos usar \((x,y,z,1)\) !
Estendendo a nossa matriz de translação de duas dimensões para três dimensões é apenas somar a \(z\) coordenada e colocar mais uma coluna:
Então temos a nossa matriz de escala para três dimensões! A única coisa que precisamos fazer foi escalar também o eixo \(z\). Porém esta é a forma da nossa matriz em coordenadas cartesianas. A nossa matriz de escala para coordenadas homogêneas será:
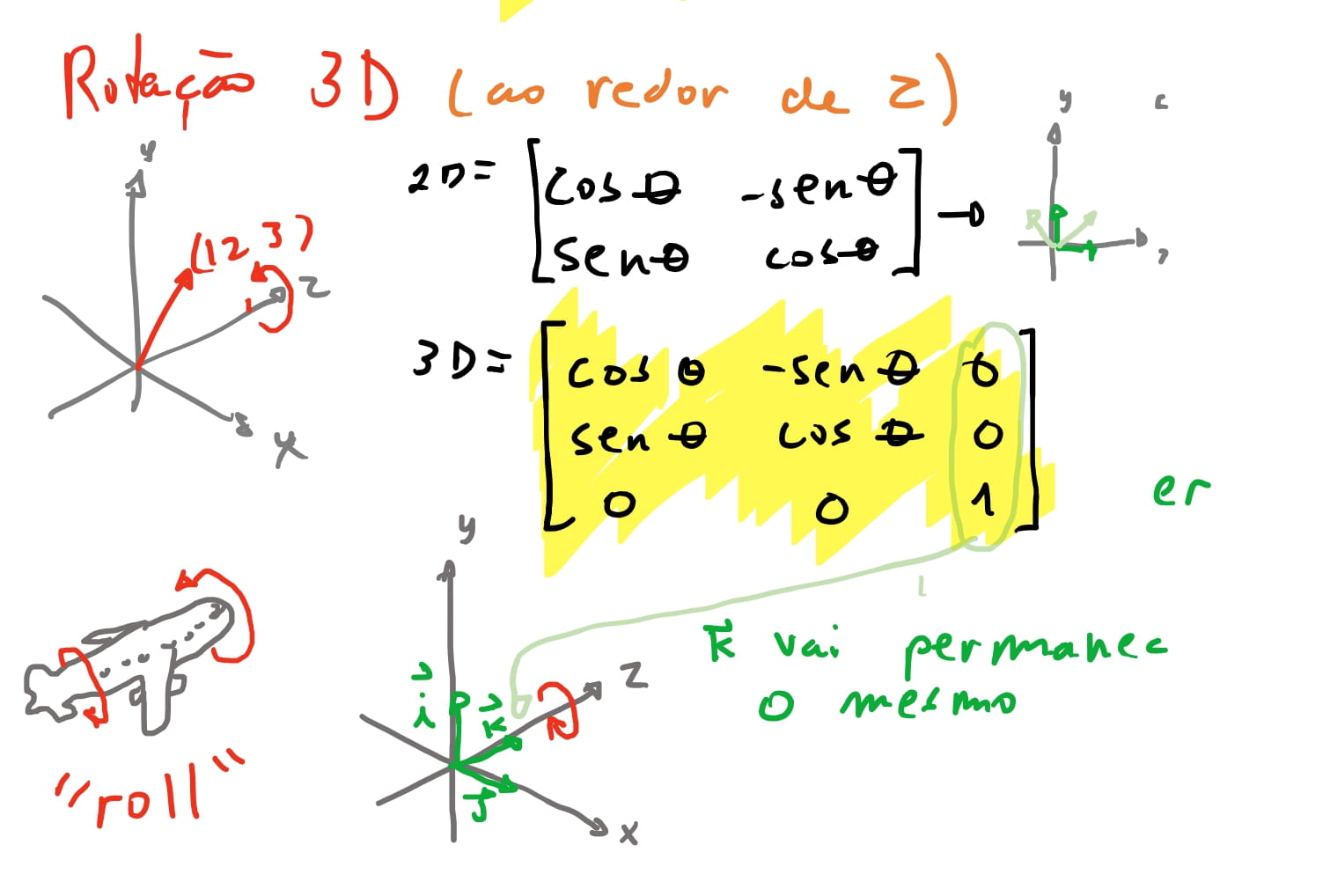
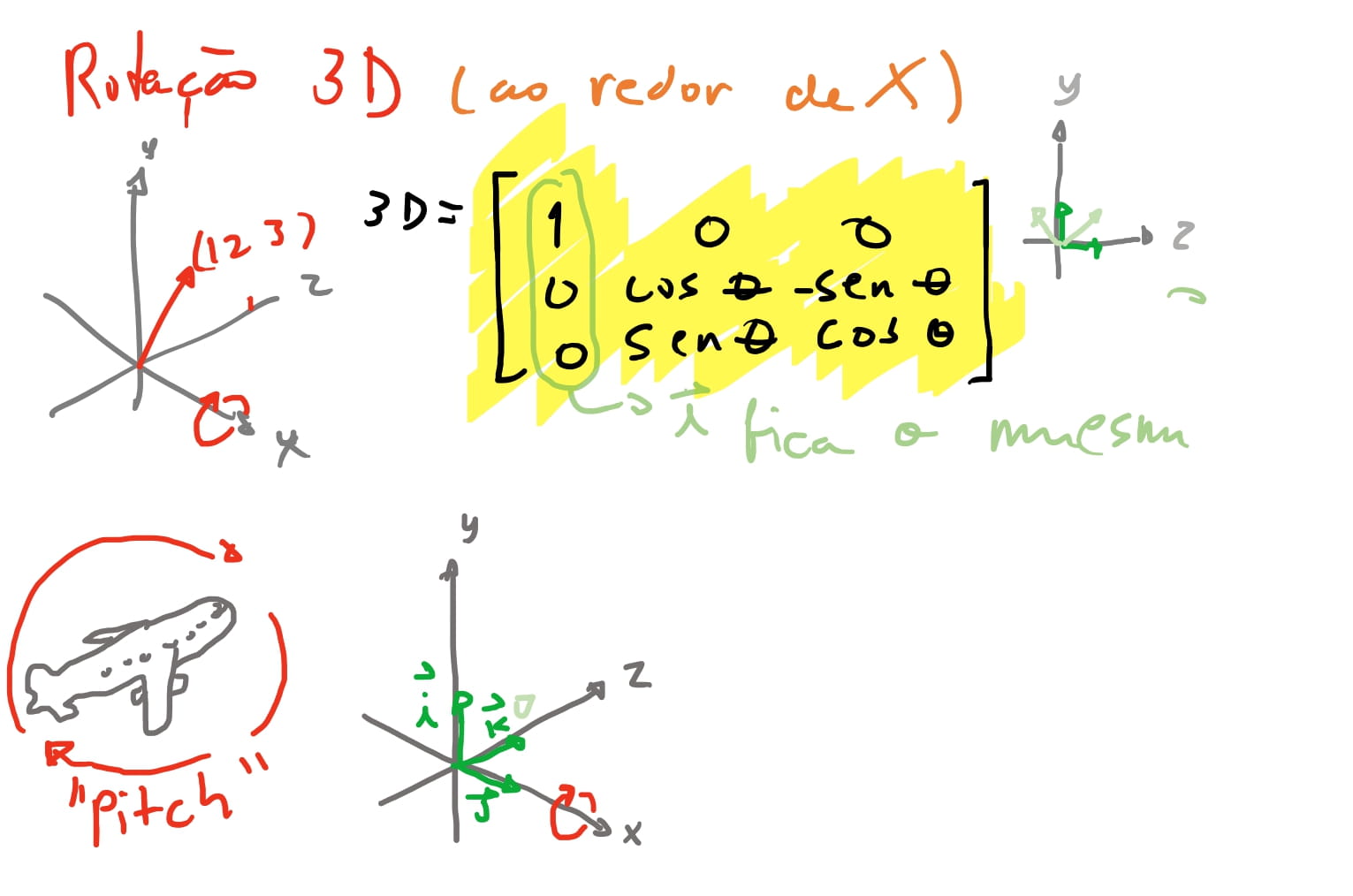
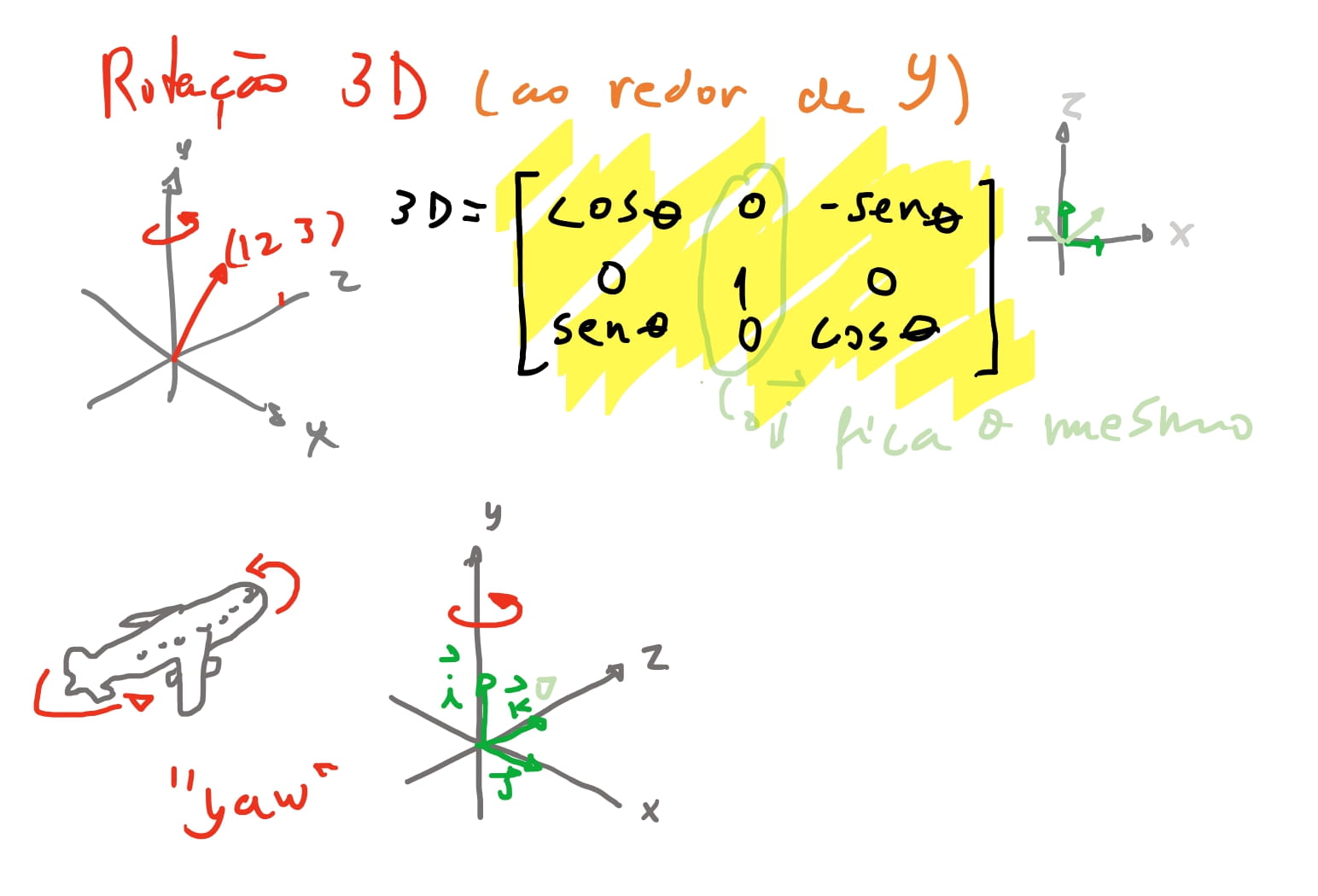
E por fim chegamos nas matrizes de rotação tridimensional. Como vimos a nossa matriz de rotação bidimensional gira dois eixos e os mantém perpendiculares. A ideia para rotação tridimensional vai ser a mesma, e portanto nos vamos ter três formas de girar: Ao redor do eixo \(x\), ao redor de \(y\) e ao redor de \(z\). Em outras palavras: vamos girar apenas dois eixos e o outro se mantém o mesmo!
Ao redor do eixo \(z\) o vetor \(\vec{k}\) se mantém inalterado \((0, 0, 1)\) enquanto os outros dois giram. E agora que temos nossa matriz, vamos igual as matrizes de escala e rotação transformar em coordenadas homogêneas:
Estamos quase la! Na verdade, se a câmera não se mover, ja conseguimos mover o ponto e os vértices livremente pela cena usando nossas matrizes. Mas agora que ja fomos tão longe queremos chegar na nossa matriz de \(P_{rojeção}\) como citamos acima para justificar todo esse exercício com matrizes.
Como vimos, para projetar um ponto \((x, y, z)\) mapeamos ele para nossa tela de projeção da câmera \((\frac{x\cdot d}{z}, \frac{y\cdot d}{z}, 1)\).
Podemos então fazer uma matriz que faça essa transformação!
Vamos usar então uma propriedade das coordenadas homogêneas que começamos a usar! Usamos coordenadas homogêneas até agora para conseguirmos uma matriz de translação que pode ser multiplicada com as outras transformações. Mas o uso das coordenadas homogêneas vai além! A começar em como podemos saber se estamos falando de um ponto ou de um vetor? Apesar de um vetor poder representar um ponto no espaço, podemos querer saber de algum ponto específico. Então para conseguirmos diferenciar entre um vetor e um ponto, dado nossa coordenada homogênea \((x, y, z, w)\), se \(w = 1\) representa um ponto. E se \(w = 0\) representa um vetor. Então \(\vec{v} = (1, 2, 3, 0)\) é um vetor enquanto \(P = (1, 2, 3, 1)\) é um ponto.
Então a propriedade das coordenadas homogeneas é essa representação mista de pontos e vetores. Podemos representar a soma de dois vetores e vai resultar em um vetor: \((0, 0, 1, 0) + (1, 1, 1, 0) = (1, 1, 2, 0)\), multiplicar um vetor por um escalar \((1, 1, 1, 0) \cdot 2 = (2, 2, 2, 0)\) e vamos ter um vetor, e se subtrairmos dois pontos vamos obter um vetor \((3,2,1,1) - (1, 1,1,1) = (2, 1, 0, 0)\).
Valores de \(w>1\) representam somente outra representação do mesmo ponto. Existem infinitas representações do mesmo ponto. O ponto \((1,2,3,1)\) é igual \((2,4,6,2)\) assim como é igual à \((-4, -8, -12, -4)\). A representação \(w = 1\) é chamado de “representação canônica”.
E para transformar uma coordenada homogênea para coordenada cartesiana basta dividir o valor de \(w\) pelas outras componentes.
E como sabemos, para projetar um ponto tridimensional cartesiano no plano da camera temos que chegar na seguinte equação de projeção: \((x,y,z) \rightarrow (\frac{x\cdot d}{z}, \frac{y \cdot d}{z}, 1)\).
Se fizermos uma matriz que consegue fazer com que \(w = z\), vamos conseguir chegar em uma transformação que faria nossa coordenada homogênea projetar o ponto pela própria operação: \((x,y,z,z) \rightarrow (\frac{x}{z}, \frac{y}{z}, \frac{z}{z}, 1)\), e bastaria multiplicar por \(d\) que teríamos a nossa equação de projeção.
Então vamos ver como podemos chegar na matriz de projeção.
Acima vemos que do nosso sistema de equações, apenas o termo \(O = 1\) para matriz resultar que o valor de \(w\) do nosso vetor receba o valor de z.
Com isso temos a matriz:
Vamos testar se nossa matriz funcionará com o exemplo do cubo do post anterior usando uma instancia do nosso cubo, onde vamos coloca-lo na posição do mundo \((0,0,4)\) e projeta-lo na tela
Podemos ver que se projetar-mos os quatro pontos \(ABCD\) teremos projetados corretamente!
E quando converter-mos o vetor de coordenadas homogêneas para cartesianas, teremos finalmente o ponto projetado corretamente!
Então vamos ver como isso vai funcionar:
cubo_em_cena->:|modelo:cubo|transformacoes:|transalacao:(0,0,4)|rotacao:(30,0,0)|escala:(1,1,1)câmera:|posição:(0,0,0)|plano_proj:1funçãodesenha_cena(objetos_em_cena):paracadainstanciaemobjetos_em_cena:desenha_objeto(instancia)funçãodesenha_objeto(instancia):sejapontos_projetados=[]paracadavérticedeinstancia:vertice_homogeneo=Vetor4f(vertice.x,vertice.y,vertice.z,1)matriz_translado=Matriz4x4(vertice.transformacoes.transaldo)matriz_escala=Matriz4x4(vertice.transformacoes.escala)matriz_rotacao=Matriz4x4(vertice.transformacoes.rotacao)ponto_projetado.insere(Vetor2f(matriz_projeção*matriz_translado*matriz_rotacao*matriz_escala*vertice))paracadatrianguloeminstancia.modelo:desenha_triangulo(triangulo,pontos_projetados)// agora utilizaremos triangulo como o indice das faces como citamos no começo do textofunçãodesenha_triangulo(triangulo,pontos)://p1->p2desenha_linha(pontos[triangulo[0]],pontos[triangulo[1]])//p2->p3desenha_linha(pontos[triangulo[1]],pontos[triangulo[2]])//p3->p1desenha_linha(pontos[triangulo[2]],pontos[triangulo[1]])
E com isso ja conseguimos desenhar na tela nosso cubo !
O cubo nós renderizamos na mesma posição em que estava na cena anterior, porem, rotacionamos em relação ao eixo \(y\) em \(45º\) e escalamos \(0.5\) em todos os eixos!
Segue a nossa implementação em que comentamos como funciona nossas matrizes:
Em 1984 a banda KLF viajava pela Inglaterra fazendo exibições salas abertas de cinema queimando 1 milhão de libras. Naquela época 1 milhão de libras simbolizava a fuga da “vida cotidiana” de lutar pelo ganha pão, simbolizava a entrada em uma classe social em que não mais precisava “ganhar o pao de cada dia”, mas que o dinheiro podia render e, portanto, viver de renda. Era um valor simbólico que a banda havia queimado. O cinegrafista e amigo da dupla, não entendia muito bem o porque eles estavam fazendo e, os próprios membros alegaram que, durante o ato, nem eles também sabiam porque estavam fazendo.
Nos anos 90 a musica havia se tornado uma industria, e segundo Drummond and Cauty, a alma da musica havia sido vendida pelo mesmo peso em ouro. Então, no começo da era digital e nos primórdios dos sons sintetizados em computador, os dois tiveram uma brilhante ideia: E se fizessem uma musica pop em que não pudesse ser comercializada? Fizeram uma musica chamada The Queen and I, que criticava a democracia Inglesa e usava samples de uma musica do ABBA. A musica ganhou popularidade e com a mesma velocidade em que ganhou o publico recebeu igualmente em processos. Era genial. Na época ainda se chamavam the Jams. Acontece que a historia da vitoria da dupla Drummond e Cauty sobre o capitalismo musical virou contra eles.
KLF inovando com mais musicas digitais e iniciando gêneros musicais, ainda com a veia punk de rebelar contra a industria musical, começaram a fazer sucesso e o próprio sucesso deles era o que os levaria a queimar os 1 milhão de libras. No meio do sucesso, eles perceberam que a industria havia se adaptado, e agora os samples, que antes geravam processos, agora eram vastamente usados. A industria da musica havia se adaptado e Cauty e Drummond eram os responsáveis. No meio da fama e com riqueza e influencia que conquistaram justamente pela mesma industria que queriam destruir, queimaram os 1 milhão de libras, como protesto: Se dessem para alguma ONG, ou para alguém, o dinheiro ainda existiria e ainda continuaria existindo e tendo influencia. E portanto, na visão deles, o único jeito de eles se libertarem era queimando.
Cauty e Drummond desfizeram a banda mas seguiram suas carreiras artísticas. Ainda como verdadeiros punks. Ao se tornarem milionários, disseram que venderam sua alma para o capitalismo. E queimar, foi a sua forma de recomprar sua alma de volta, e junto dela, sua expressão artística.
A história do KLF beira o que é real e o irreal. E quando não há como definir se algo é real ou não sobra apenas os símbolos do universo que nos cerca e como interagimos com eles depende das varias formas como nós interpretamos eles. Quanto mais melhoramos o nosso rasterizador mais nos aproximamos da dificuldade de discernir o real do irreal. E este texto vai tratar da primeira parte de como vamos “dar realidade” aos objetos. Toda a parte que tratamos até agora apenas lidou com a representação e projeção. Mas o que da o realismo é como “preenchemos” os triângulos em cada um dos nossos objetos. Cada pixel deve receber a cor certa para atingirmos o realismo.
Neste texto vamos construir nosso algoritmo que finalmente vai rasterizar os triângulos que compõe nossa cena. Rasterizar é o ator de preencher os triângulos. Então precisamos elaborar um algoritmo que consiga preencher qualquer triangulo independente da sua orientação. Mas só preencher não será suficiente. Vamos elaborar algum algoritmo para saber a ordem em que desenhamos estes triângulos, pois, depois que projetarmos, há faces que não serão visíveis.
Como vamos preencher nossos modelos ?
Para preencher nosso modelo precisamos preencher todas as faces com as cores específicas. Neste texto vamos discutir primeiro como podemos preencher as faces dos triângulos. Nos próximos vamos ver como podemos preencher esses triângulos com cores específicas para reproduzirmos efeitos de iluminação e textura. Mas por enquanto, vamos nos conter a preencher as faces.
Então queremos pensar em um algoritmo para preenchera as faces dos triângulos. Depois que conseguirmos ainda vai acontecer um fenômeno: os triângulos vao ser coloridos pela ordem que foram definidos. Então precisamos pensar em alguma forma auxiliar para colorir os triângulos que estão mais próximos da câmera somente.
Para preencher triângulos existem vários algoritmos conhecidos. O que vamos usar aqui inicialmente vamos usar a mesma ideia por trás de como desenhamos linhas no nosso primeiro texto. Nós precisamos saber quais são as equações de reta entre os vértices dos triângulos e isso vai permitir nós sabermos quais os pontos estão nas arestas do triangulo. Com essa aresta, se nos iterarmos pela altura do triangulo, para preencher o triangulo vai bastar desenhar uma linha de aresta em aresta para cada valor da altura do triangulo.
\begin{algorithm}
\caption{PrencherTriangulo, onde $V_1, V_2, V_3$ são os vértices de um triangulo}
\begin{algorithmic}
\PROCEDURE{PreencherTriangulo}{$V_1, V_2, V_3$}
\STATE $V_1, V_2, V_3$ $\leftarrow$ \CALL{Ordenar}{$V_1.y, V_2.y, V_3.y$}
\FOR{$V_1$ \TO $V_3$}
\STATE{Computar $x$-coordenada das arestas para o atual $y$}
\STATE{Pinte o pixel entre $x'$ e $x''$ }
\ENDFOR
\ENDPROCEDURE
\end{algorithmic}
\end{algorithm}
E ai vai bastar que a gente consiga controlar qual face vai ser desenhada. Existindo a técnica do pintor: O pintor quando vai produzir seus quadros primeiro desenha o fundo, depois o que ta um pouco a frente do fundo e por fim o que está mais próximo. Podemos usar este algoritmo. O problema é que existem figuras que o algoritmo do pintor ainda não vai conseguir resolver. Então uma melhoria no algoritmo do pintor seria que ao invés de pintar triangulo por triangulo dada a profundidade, pintarmos um pixel por profundidade. Então sempre coloríamos o pixel com a \(z\)-coordenada mais próxima da câmera.
Por fim, há portanto de se pensar que existem inúmeras faces do nosso modelo que nunca seriam vistas, e de toda forma, estariam sendo pintadas com o algorismo do pintor. Então para melhorar a eficiência, poderíamos saber quais sao as faces que vao ser pintadas e remover as que nao serão. Sendo este algoritmo chamado de face culling. Ao combinarmos estes algoritmos vamos conseguir visualizar nossos modelos tridimensionais propriamente coloridos!
Então vamos pensar em como podemos preencher um triangulo. Uma ideia que temos que fixar ja desde o começo é que nossa tela de pixels é discreta. Isto é: todos os indices dos pixels são valores inteiros. Não existe um pixel \(3.4\) ou \(1.15\). Então temos que desde ja pensarmos que qualquer valor racional deve ser convertido para um inteiro.
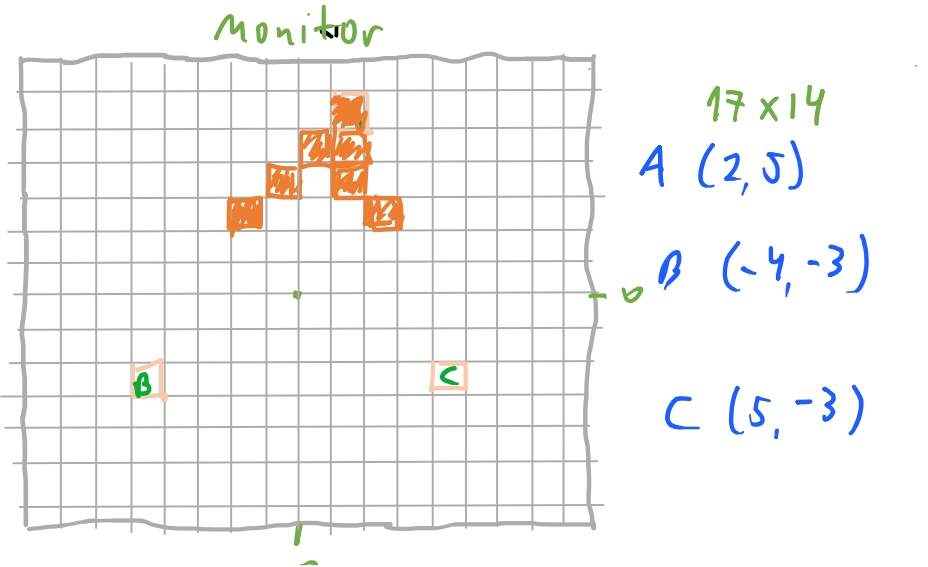
Então vamos ver como podemos chegar no algoritmo para desenhar nosso triangulo. Vimos acima a ideia por tras. Agora vamos ver como podemos implementa-la. Então imagine que temos um triangulo com os vértices \(A (2, 5)\) \(B (-4, -3)\) e \(C (5, -3)\). _OBS: Apenas para relembrar que no primeiro texto e no texto de projeção, nós centralizamos as coordenadas dos pixels da tela para que pudéssemos mapear a nossa tela de projeção _ .
Como vamos iterar sobre o eixo-\(y\), queremos saber quais são os valores de \(x\) para cada valor de \(y\). E para nossa sorte, assim como vimos no primeiro post, podemos usar equações de reta entre dois pontos para determinar a equação linear que conecta os dois pontos. Quando tivermos esta equação, conseguiremos calcular o valor das arestas do triangulo dado uma \(y\)-coordenada. Vamos ver como isso vai funcionar:
Queremos então iterar sobre o intervalo do maior valor de \(y\) dos vertices até o menor valor de \(y\) dos vertices. No nosso exemplo acima, queremos ir de \(5\) até \(-3\). Então temos as nossas retas entre \(\overline{AB} \rightarrow y = \frac{4x}{3} + \frac{7}{3}\) e temos que a nossa reta \(\overline{AC} \rightarrow y = - \frac{8x}{3} + \frac{31}{3}\), e conseguimos calcular alguns valores de \(x\) para cada valor de \(y\). E portanto, como podemos ver quando \(y=2\) temos que \(x= - \frac{1}{4}\) para a nossa reta \(\overline{AB}\) e temos que \(x=\frac{25}{8}\) para a reta \(\overline{AC}\). A regra que usamos é arredondar para baixo para o primeiro inteiro. Então temos que \(x = -1\) para \(\overline{AB}\) e \(x = 3\) para \(\overline{AC}\). Agora basta iterar entre \(-1\) e \(3\) e preencher cada pixel. E assim temos a base do nosso algoritmo.
casos específicos
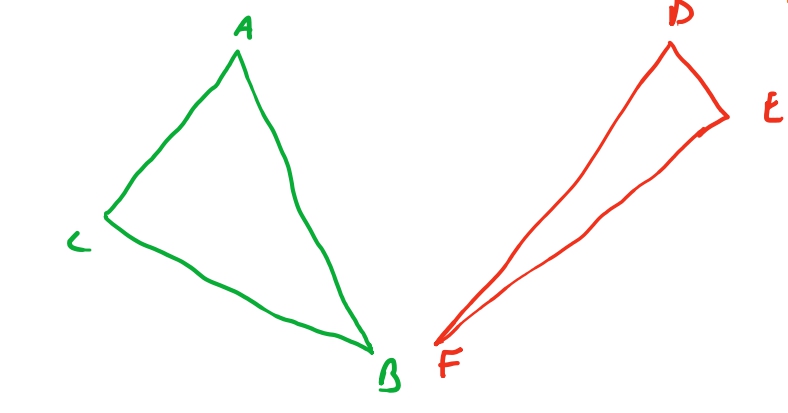
Para iterar de aresta em aresta, vão existir casos como os triângulos acima em que não necessariamente só precisamos usar duas retas, mas as três retas. O triangulo \(ABC\), possui o lado \(AB\) maior que \(AC\) e \(BC\). Então quando formos iterar entre as arestas, algum momento iteraríamos sobre a aresta \(AC\) até \(AB\), e depois de \(CB\) até \(AB\).
Com isso em mente vamos conseguir agora preencher qualquer triangulo. Então vamos começar a elaborar nosso algoritmo.
Vamos precisar de alguma ferramenta para conseguirmos calcular as nossas equações de reta. Apesar de nos exemplos anteriores nós chegamos em um sistema de equações lineares bem simples para calcular as retas, resolver sistemas lineares para cada triangulo seria bastante complicado. Então vamos ver se conseguimos pensar em alguma ferramenta que possa nos ajudar.
O que precisamos? Queremos alguma forma de para cada \(y\), encontrar um \(x\) das arestas do triangulo. Então vamos assumir que temos uma função \(f(y)\), que para cada \(y\), retorna um \(x\) da aresta do triangulo. Então quando a iteração for acontecer, teremos os valores de \(y\) dos quais estamos iterando, mas precisamos calcular \(x\). Então \(x\) é uma variável dependente de \(y\), e \(y\), neste caso, é uma variável independente.
Interpolação linear
Conseguimos então chegar que, haverá uma reta, da aresta do triangulo, que vamos querer encontrar um ponto \(P\) entre os vértices do triangulo para um dado valor de \(y\). Esta técnica é conhecida como interpolação linear, e vamos usar bastante essa técnica daqui em diante.
Na imagem acima, podemos visualizar o triangulo formado pelo vertices que queremos calcular a reta. Neste triangulo o lado oposto ao angulo \(\theta\) é \(y_2 - y_1\), e o angulo adjacente ao angulo é o lado \(x_2 - x_1\). A razão do lado oposto pelo adjacente é a tangente do angulo \(\theta\). Conseguimos perceber que o triangulo formado por \(P_1\) \(P_2\) é proporcional ao triangulo formado por \(P_1\) e o ponto \(P\) que procuramos. Então conseguimos chegar na seguinte equação:
Dessa igualdade conseguimos isolar qual vai ser a nossa variável independe e qual vai ser a nossa variável dependente. No nosso algoritmo, vamos ter o valor de \(y\), mas queremos saber qual o valor de \(x\). Então, como dissemos acima, \(x\) vai ser nossa variável dependente. Então vamos resolver essa igualdade para \(x\).
E podemos enxergar que essa equação realmente é uma equação de reta, da forma \(x = a(y-y_1) + x_1\), ja que \(x_1\) é uma constante, e \(a = \frac{y_2 - y_1}{x_2 - x_1}\) também é .
Vamos testar e ver como essa equação funciona:
E agora podemos generalizar essa equação, porque não necessariamente só poderíamos esta equação da perspectiva de \(y\) é independente e \(x\) é dependente. Poderíamos usar a mesma equação em que os papeis são reversos: em que \(x\) é independente e \(y\) é dependente. Então vamos generalizar a equação. Seja \(i\) a variavel independente e \(d\) a variavel dependente:
Com a nossa função de interpolação linear(também conhecida como lerp)em mãos, podemos agora nos concentrar em preencher as faces.
Então vamos esboçar o algoritmo. Para iterar em cada linha que compõe o triangulo, precisamos saber quais sao os vértices com as maiores \(y\)-coordenada. Então vamos ordenar os vértices e com o maior e o menos sabemos quais sao as linhas que vamos iterar.
Com cada linha, vamos usar a função de lerp e descobrir quais são as coordenadas de onde começa e termina cada aresta daquela linha. Então vamos iterar entre as arestas e vamos preencher os pixels.
Para lidar com os triângulos que citamos, podemos descobrir quais sao os dois menores lados do triangulo. Sabendo quais são, podemos junta-los e considerar que sao apenas um lado. E assim o algoritmo funciona da mesma forma.
E para finalizar, para iterarmos de aresta para aresta, temos que descobrir qual aresta tem o \(x\)-coordenada menor e qual tem a maior. E entao iteramos da menor para a maior colocando os pixels na dada coordenada.
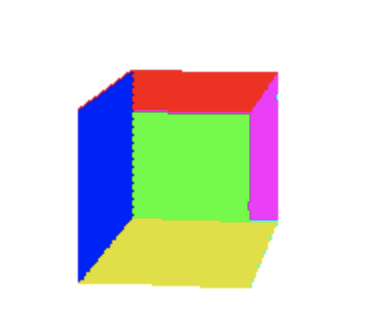
O que estamos fazendo é portanto, calcular qual a aresta mais à esquerda e mais à direita e iterando sobre ela. Podemos tambem chamar drawLine(xMaisAEsquerda, y, xMaisADireita,y) no lugar do segundo for no nosso algoritmo. E agora conseguimos preencher as faces de um triangulo como podemos ver abaixo:
Faces tridimensionais
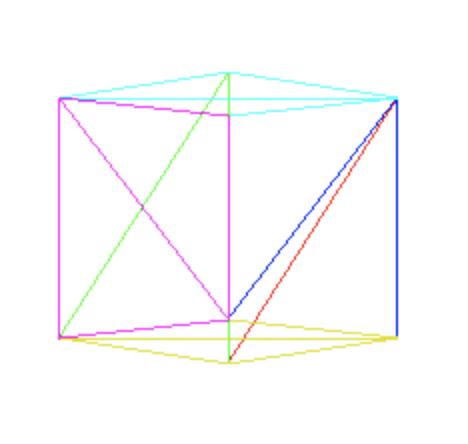
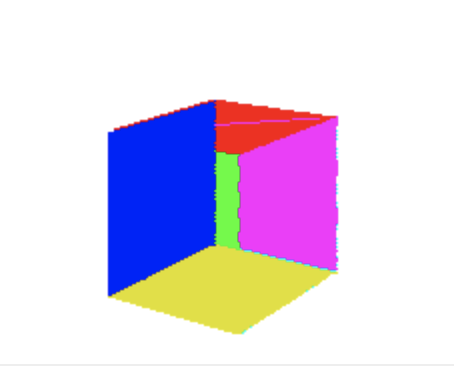
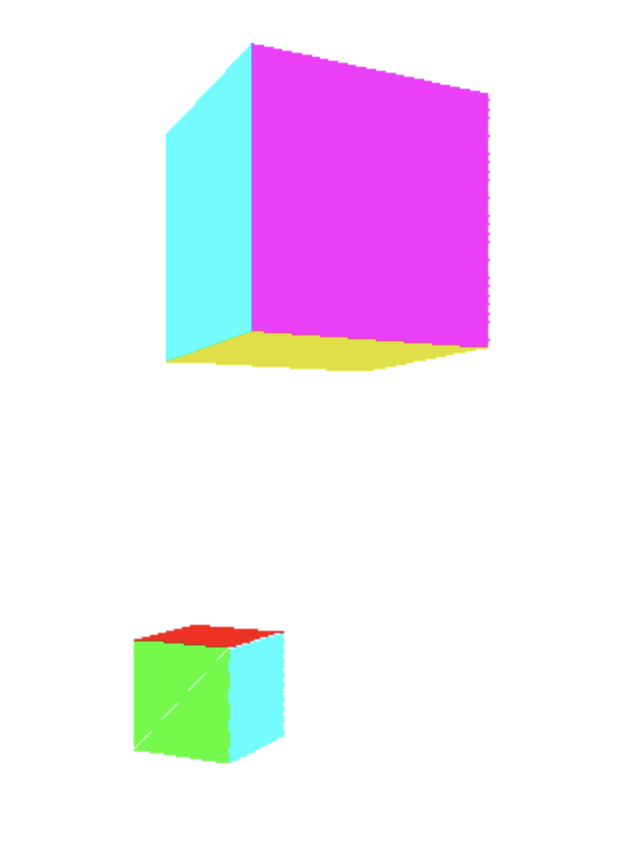
Se usarmos este nosso recente algoritmo de preencher triangulos para preencher os triangulos das faces do cubo que chegamos no texto anterior, podemos obter um resultado parecido com esse:
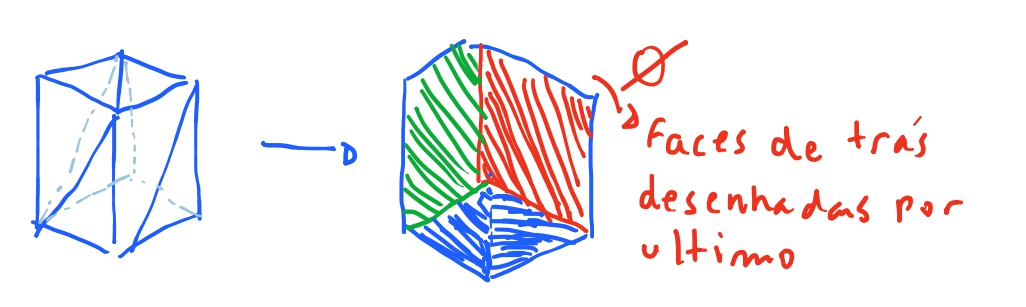
E isso pode se dar pela a ordem em que os triângulos foram desenhados. Os triangulos do fundo do cubo estao sendo desenhados por ultimo, ou casos similares. Mas mesmo descrevendo a ordem “correta”, a ordem ia depender do ponto de vista da camera. E se rotacionassemos o cubo novamente veriamos o poligono desenhado incorretamente. Para resolvermos este inconveniente, vamos criar uma ordem de pintura. E a solução é muito simples. Desenhamos o que esta mais longe primeiro, e o que esta mais perto da camera por ultimo. Assim sempre garantimos que a face da frente sempre esteja na frente.
Podemos ver qual triangulo tem a \(z\)-coordenada menor, e salvar qual foi a mais “proxima”. Caso o novo triangulo esteja mais proximo, atualizamos este valor com o valor menor, e desenhamos este triangulo em frente. Este algoritmo chama-se algoritmo do pintor. Podemos implementar ele facilmente apenas salvando qual a \(z\)-coordenada antes de “ignorar” este valor durante a projecão. Porem, acontece um problema com o algoritmo do pintor que queremos evitar desde já.
Caso alguma cena possua faces mais complexas, o algoritmo do pintor não produziria imagens corretas. Então pra isso, ao inves de saber qual a face esta mais a frente, vamos melhorar um pouco a precisao do algoritmo do pintor e, calcularemos entao, qual pixel está mais a frente ao inves do triangulo inteiro. Para descobrir-mos isso, vamos usar a nossa função de lerp!
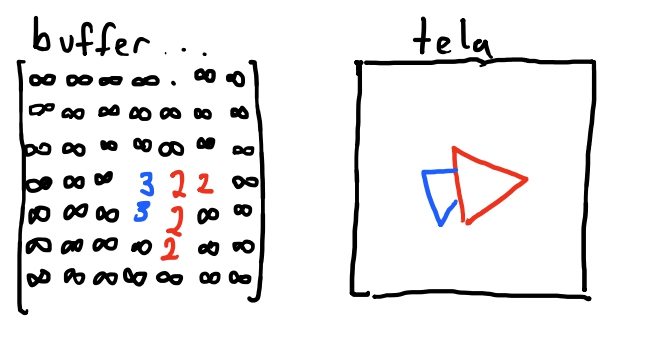
E para isso, nós estamos ainda iterando sobre o eixo \(y\) do triangulo, de baixo para cima. Então nossa variavel \(y\) é a nossa variavel independente. E queremos saber, para cada \(y\), qual é o valor da \(z\) coordenada respectiva daquela \(y\)-coordenada. E então, teremos um buffer, isto é, uma memoria para cada pixel da tela. E entao, para cada pixel vamos computar qual a distancia em \(z\) da camera. Caso seja menor do que estava salvo no buffer para aquele pixel, atualizamos o buffer com o novo valor e pintamos aquele pixel. Do contrario, o pixel colorido ja é o mais proximo da camera.
Vamos precisar interpolar em \(z\) para cada \(y\) pois o triangulo pode ter alguma rotação em algum eixo.
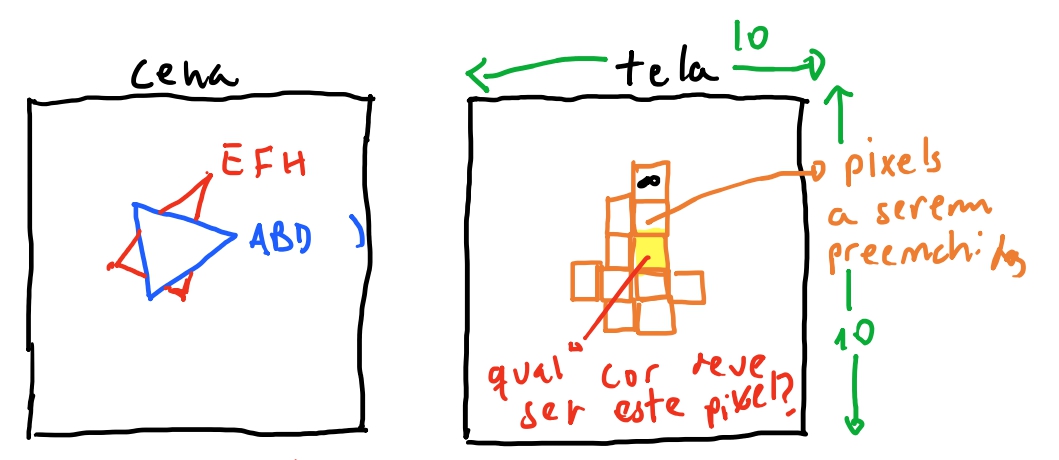
Imaginando o nosso cubo de exemplo do capitulo de projeção, e se usassemos os triangulos \(EFH\) e \(ABD\), teriamos como exemplo os seguintes pontos apos as equações de projeção. (Assumindo apenas a transformação neste cubo do exemplo, seria uma translação para \((0,0,4)\).)
Como não houve nenhuma rotação dos triangulos, eles estão paralelos entre sí, e portanto o lerp de \(z\), para qualquer \(y\) será \(4\).
Mas conseguimos pensar no triangulo \(AED\).
Uma coisa que vocês vão perceber nas contas acima, é que a interpolação linear esta crescendo rápido demais. O que pode até funcionar, mas vamos perceber que a relação entre \(y\) e \(z\) não é linear!
Vamos investigar o porque! Vamos tentar calcular qual o valor de \(z\) em relação ao ponto \((x', y')\) no plano de projeção. Sabemos que a equação do plano é dada por \(Ax + By + Cz + D =0\). E sabemos que para qualquer ponto no nosso mundo, projetamos este ponto \((x, y, z)\) no nosso plano de projeção com as equações : \(x' = \frac{x * d}{z}\) e \(y' = \frac{y * d }{z}\). Então vamos ver qual a relação do ponto projetado, com a coordenada \(z\).
Então podemos ver que, a relação entre os pontos projetados e \(z\) original é \(z = \frac{-dD}{Ax'+ By' + dC}\). E o que faz sentido: quando projetamos, o ponto no plano de projeção é inversamente proporcional ao eixo \(z\). Porem esta não é uma equação linear.
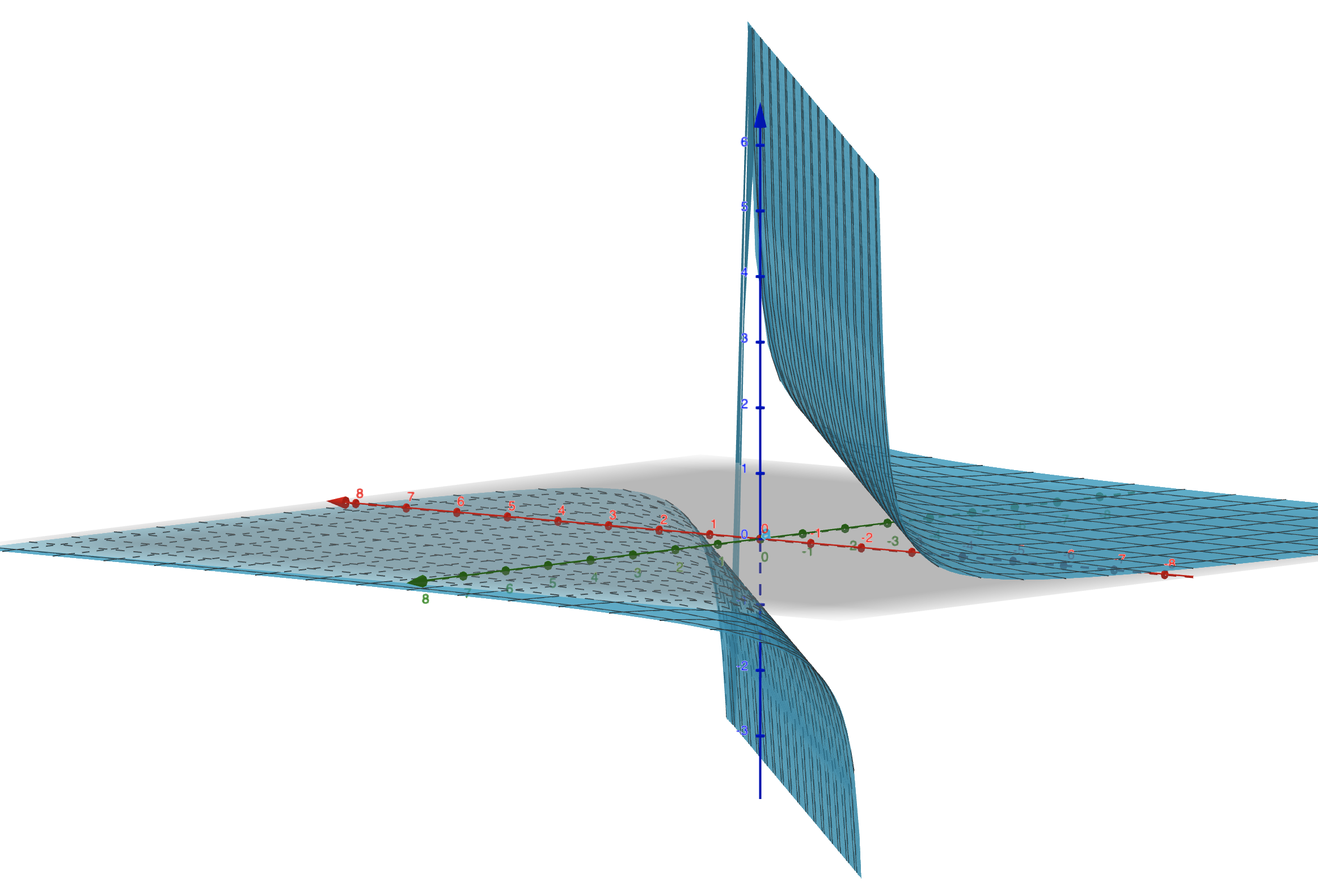
Se nós desenharmos o gráfico de \(z\) teremos a seguinte figura tridimensional:
O que claramente não é linear! Como não é linear, se tentarmos interpolar linearmente \(z\) não vamos chegar proximo dos valores reais. Mas, conseguimos perceber que o comportamento da inversa, \(\frac{1}{z}\) é linear:
\[\frac{1}{z} = \frac{Ax' + By' + dC}{-dD}\]
Então ao inves de usarmos \(z\) para interpolar, vamos usar \(\frac{1}{z}\) e vamos conseguir interpolar linearmente. Então a alteração em nosso algoritmo de \(z\)-buffer vai funcionar ao contrario: Vamos iniciar todas as posições do nosso buffer com \(0\) e vamos comparar o valor com o inverso, ao inves de compararmos se o valor interpolado é menor, checaremos se o valor é maior do que o salvo no buffer.
Vamos ver a implementação
\begin{algorithm}
\caption{PrencherTriangulo, onde teremos um buffer global chamado zBuffer}
\begin{algorithmic}
\PROCEDURE{PreencherTriangulo}{$V1, V2, V3$}
\STATE $X_{valores}\overline{V1V2} = $ \CALL{LERP}{$V1.y, V2.y, V1.x, V2.x$}
\STATE $X_{valores}\overline{V2V3} = $ \CALL{LERP}{$V2.y, V3.y, V2.x, V3.x$}
\STATE $X_{valores}\overline{V1V3} = $ \CALL{LERP}{$V1.y, V3.y, V1.x, V3.x$}
\STATE $z_{valores}\overline{V1V2} = $ \CALL{LERP}{$V1.y, V2.y, V1.z, V2.z$}
\STATE $z_{valores}\overline{V2V3} = $ \CALL{LERP}{$V2.y, V3.y, V2.z, V3.z$}
\STATE $z_{valores}\overline{V1V3} = $ \CALL{LERP}{$V1.y, V3.y, V1.z, V3.z$}
\STATE $X_{valores}\overline{V1V2V3}$ = $ X_{valores}V1V2 \cup X_{valores}V2V3 $
\STATE pontoMédio = \CALL{size}{$X_{valores}V1V2V3$} $ \div 2$
\IF{$X_{valores}V1V2V3[pontoMédio] > X_{valores}V1V3$}
\STATE $x_{valor}AEsquerda$ = $X_{valores}V1V2V3$
\STATE $x_{valor}ADireita$= $X_{valores}V1V3$
\STATE a mesma coisa para os $z_{valores}$
\ELSE
\STATE $x_{valor}ADireita$ = $X_{valores}V1V2V3$
\STATE $x_{valor}AEsquerda$= $X_{valores}V1V3$
\STATE a mesma coisa para os $z_{valores}$
\ENDIF
\FOR{$V_1$ \TO $V3$ em $y$}
\STATE $z_{Scan} = $ \CALL{LERP}{$x_{maisEsquerda}, x_{maisDireita}, z_{maisAEsquerda}, z_{maisADireita}$}
\FOR{$x_{mais a esquerda}$ \TO $x_{mais a direita}$}
\IF{$zBuffer[x][y] < z_{Scan}[x][y] $}
\STATE \CALL{ponhaPixel}{$x, y$}
\STATE $zBuffer[x][y] = z_{Scan}[x][y]$
\ENDIF
\ENDFOR
\ENDFOR
\ENDPROCEDURE
\end{algorithmic}
\end{algorithm}
Ou seja, nesta ultima versão atualizada do algoritmo vamos interpolar linearmente \(\frac{1}{z}\) em relação a variavel independente \(y\). Com isso saberemos qual o \(z\)-coordenada de cada \(y\) coordenada pertecente ao triangulo que está sendo preenchido. Quando formos iterear sob cada linha do triangulo, vamos novamente computar qual o \(z\)-coordenada de cada pixel chamando LERP(x_mais_a_esquerda, x_mais_a_direita, z_mais_a_esquerda, z_mais_a_direita). Dessa forma vamos saber quais os valores de \(z\) para cada pixel. Então vamos conseguir atualizar nosso z- Buffer para cada pixel. E se o pixel computado for maior que o pixel atual, então colorimos.
Segue uma implementacão que ja conseguimos desenhar as faces:
E as faces ocultas?
O algoritmo de z-buffering nos garante que as faces mais proximas da camera serão desenhadas por ultimo. O que ja garante que os triangulos serão propriamente desenhados.
Porem, ainda há um excesso de trabalho pois os triangulos que estao nas faces “ocultas”, isto é, as faces que estão atras dos triangulos desenhados tambem são desenhados, porem, no fim, são redesenhados por cima pelos triangulos mais proximos. Porem conseguimos pensar em um algoritmo que evita esse retrabalho e evitar esse disperdício de computação com um pouco de algebra linear.
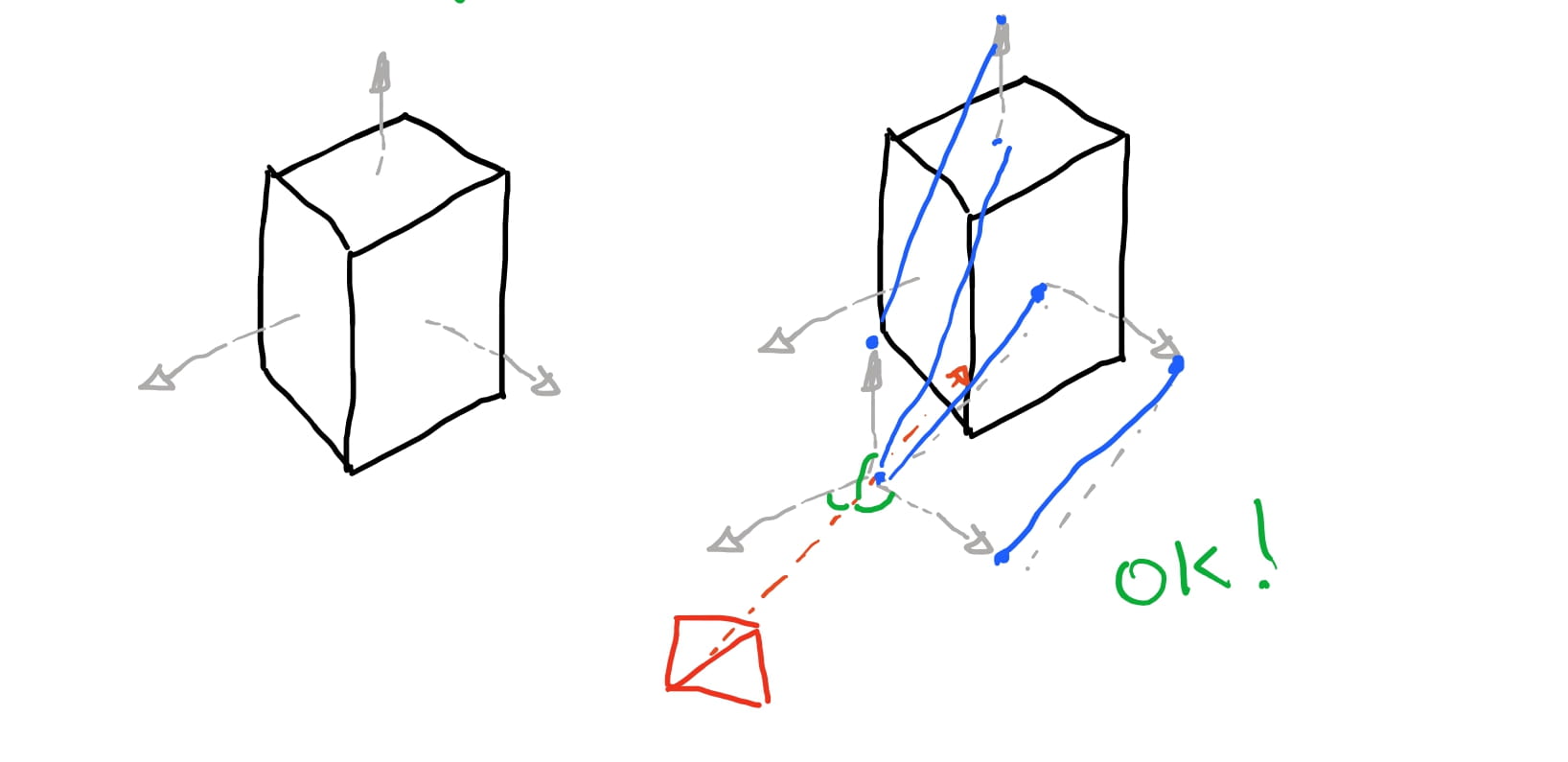
Para removermos as faces ocultas vamos usar algumas propriedades de algebra linear. Primeiro vamos descrever a ideia: O que queremos é saber quais são as faces que estao voltadas na direção da camera. As demais faces não vao estar voltadas para a camera vamos ignorar. Então vamos imaginar que conseguimos ter uma seta em cada face do poligono apontando na direção em que ela esta voltada.
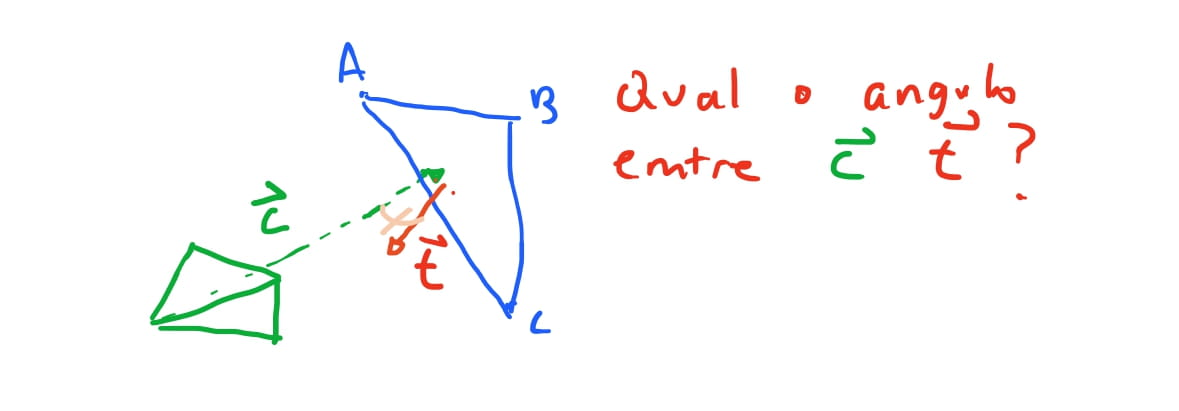
Então imagine que temos uma “seta” que indica qual a direção que a camera está observando a nossa cena. Se a seta tem um angulo menor que \(90\) graus em relação a nossa camera, significa que essa face está na direção da camera. Caso contrário, ela está para tras e portanto a nossa camera não esta vendo esta face.
Felizmente conseguimos obter essas “setas” e calcular os angulos entre as retas e vetores com certa facilidade. Podemos obter vetores como vimos nos textos poassados subtraindo um ponto de outro ponto. Podemos então para cada triangulo do nosso cubo obter quais são os vetores da face do triangulo. Imaginando nosso triangulo \(ABC\), podemos obter os vetores \(AB = B - A\), \(BC = C - A\) e \(CA = A - C\).
Em algebra linear existe uma operação que dado dois vetores nos dá qual o plano que contem ambos os vetores. O resultado dessa operação é um vetor que é ortogonal aos dois vetores ao mesmo tempo. Esta operação é chamada de cross product , ou produto vetorial. Então temos o vetor perpendicular a face do triangulo. Agora precisamos saber como medir o angulo entre esse vetor e o vetor da camera.
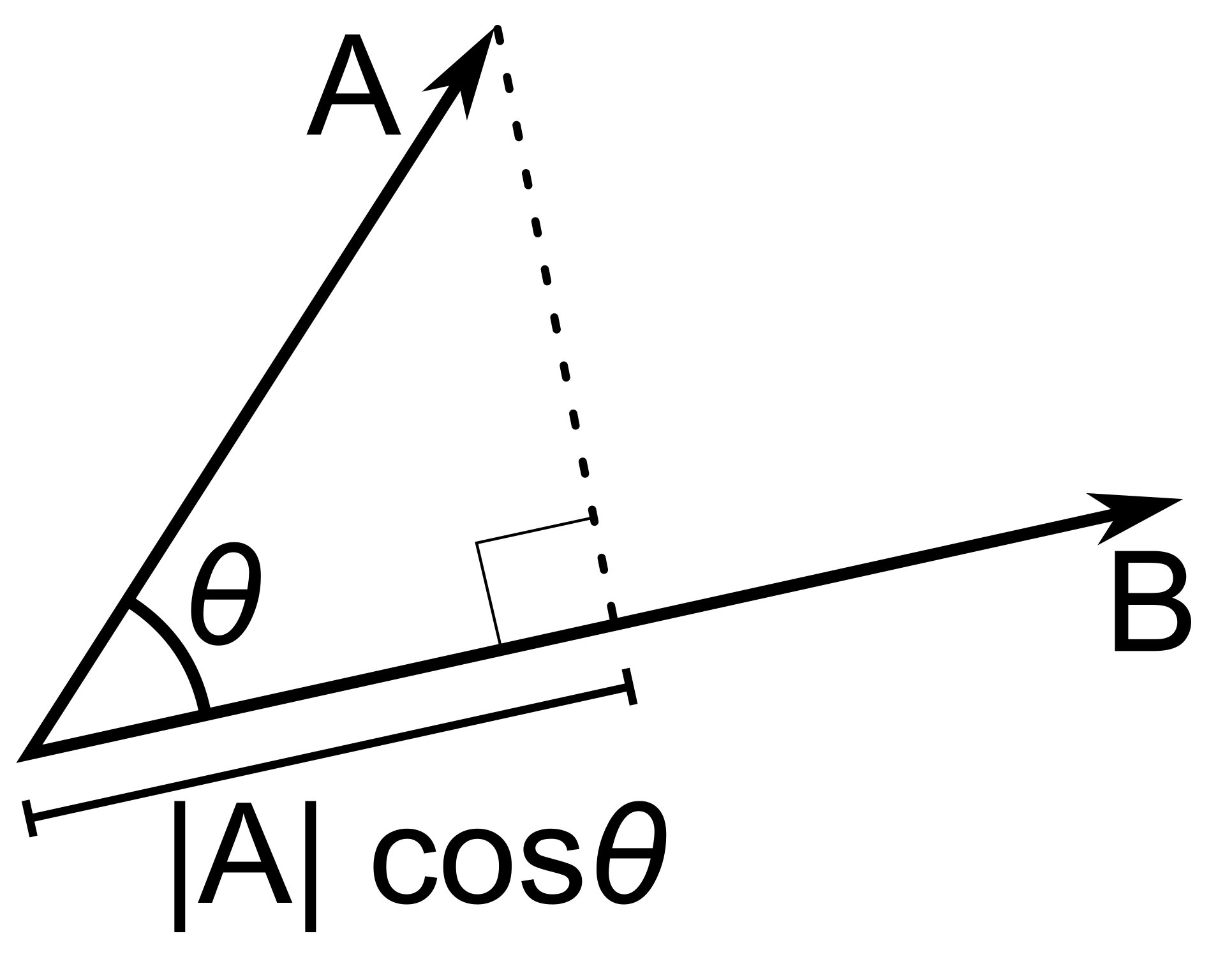
Conseguimos medir o angulo de dois vetores com o dot product, ou produto escalar de dois vetores. A ideia do produto escalar é bem simples: dado dois vetores, quando projetaoms um ao outro, o vetor projetado é um multiplo de \(cos \theta\). Então conseguimos saber qual o angulo entre dois vetores usando o produto escalar dos dois vetores. Caso o produto escalar dividido pela magnitude dos dois vetores seja maior do que o angulo que estamos esperando (\(90\)), então sabemos que esta face esta voltadda para longe da camera.
Vamos ver melhor como isso funciona:
Vamos novamente usar nosso cubo base depois de ser transladado em nossa cena, mas antes de ser projetado. Com a ideia que apresentamos acima, queremos então computar qual é o vetor do plano do triangulo \(ABC\) de uma das faces do cubo.
Então queremos calcular qual o vetor \(\vec{C}\) que aponta da camera para a face \(ABC\), e calcular qual o angulo entre os dois. Para calcularmos o vetor da face do triangulo \(ABC\) vamos usar o produto vetorial. O produto vetorial resulta em um novo vetor perpendicular aos dois vetores que foram computados. Então nós precisamos encontrar dois vetores que estao no triangulo. Para isso podemos usar as arestas dos triangulos como vetores. O vetor \(\vec{AB}\) pode ser obtido como vimos acima, \(\vec{AB} = B - A\). E, similarmente, \(\vec{BC} = C - A\). Se fizermos o produto vetorial \(\vec{AB} \times \vec{BC} = \vec{n}\) onde \(\vec{n}\) é o vetor perpendicular à \(\vec{AB}\) e \(\vec{BC}\) simultaneamente.
Para calcularmos o vetor da camera para o triangulo, poderiamos usar qualquer vertice do triangulo, mas para sermos mais precisos, podemos apontar a camera para o centro do triangulo. Para calcularmos o centro do triangulo podemos fazer uma media das componentes de cada vértice do triangulo e encontrar o ponto-medio do triangulo, tambem chamado de baricentro. E podemos apontar a camera para o baricentro do triangulo.
Assumimos que a nossa camera se encontra na origem \(O(0,0,0)\), e o baricentro do triangulo \(ABC\) é o ponto \((\frac{1}{3}, \frac{1}{3}, 3)\). Então o vetor que aponta da origem da camera para o baricentro é o vetor \(\vec{CPm} = (0, -4, 0)\).
Como podemos computar qual o angulo entre \(\vec{CPm}\) e \(\vec{n}\) ? O produto escalar entre dois vetores funciona como a “projeção” de um vetor sob o outro. E essa projeção é proporcional ao \(\cos\) do angulo formado entre os dois vetores.
Então dado dois vetores \(\vec{A}\) e \(\vec{B}\), o produto escalar é \(\vec{A} \cdot \vec{B} = \left\Vert \vec{A} \right\Vert \left\Vert \vec{B} \right\Vert \cos \theta\), onde \(\left\Vert \vec{A} \right\Vert\) é a magnitude, isto é, o comprimento do vetor \(\vec{A}\).
Isso significa que conseguimos saber o valor do \(\cos\) do angulo formado entre dois vetores. Poderiamos obter o angulo com a função inversa do \(\arccos\), porem, conseguimos saber apenas com o \(\cos\) se o vetor esta em um intervalo esperado. Assim, conseguimos obter que, seja \(\theta\) o angulo entre os nossos vetores \(\vec{C}\) e \(\vec{CPm}\), temos \(\cos \theta = \frac{ \vec{CPm} \cdot \vec{n} }{ \left\Vert \vec{n} \right\Vert \left\Vert \vec{CPm} \right\Vert }\).
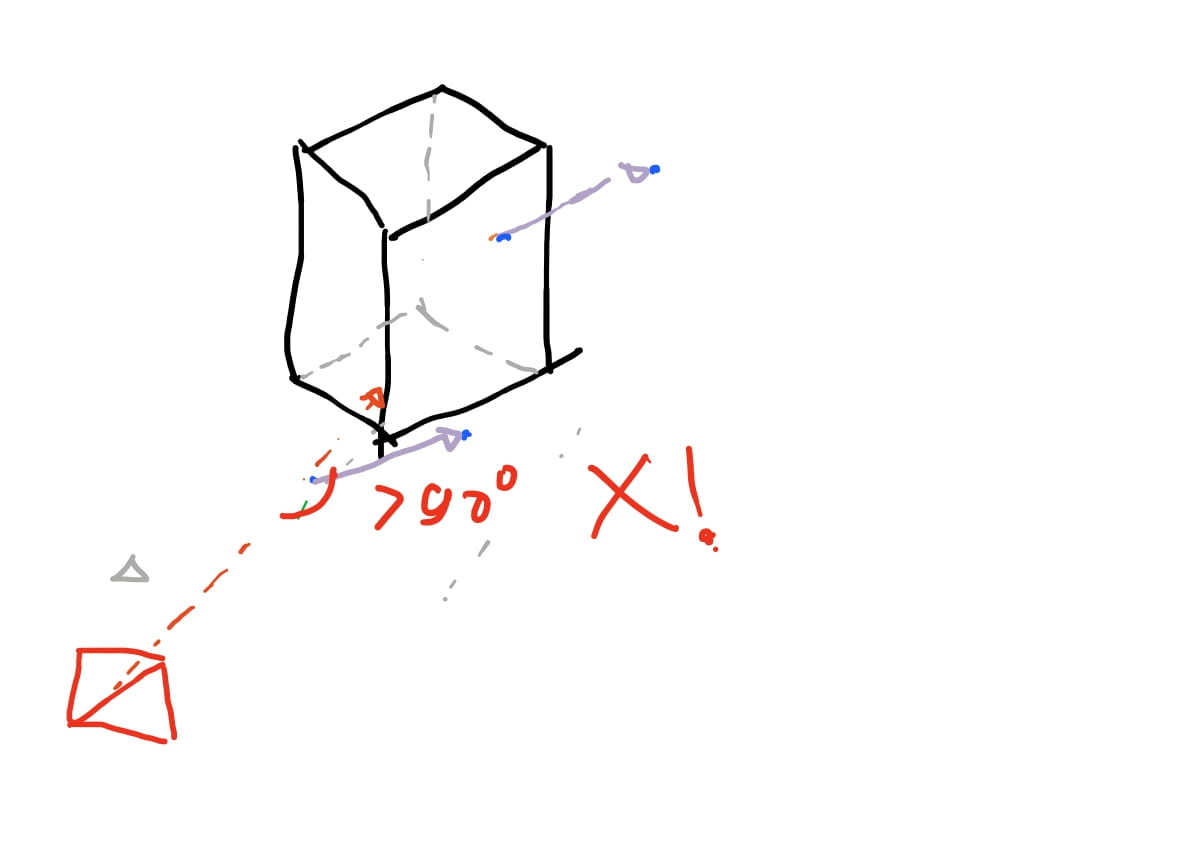
Com isso conseguimos inferir o seguinte: Se o \(\cos \theta > 0\), ou seja, positivo, implica que a face do triangulo está na direção da camera. Caso \(\cos \theta < 0\) implica que a face do triangulo está apontando na direção oposta da camera, e portanto, não é possivel ve-la.
E isso faz aparecer uma propriedade importante: Como precisamos computar os vetores com as arestas dos triangulos, \(\vec{AB}\), \(\vec{BC}\) …etc, então é esperado a mesma ordem dos vertices seja dada. Podemos usar o padrao de que os vertices do modelo sejam definidos no sentido horario para todos os triangulos, imaginando que, a face esteja na direção da camera. Exemplo:
Chamamos atenção para este detalhe pois cada ferramenta de modelagem pode usar uma ordenação diferente, e desta forma, os vetores perpendiculares dos triangulos podem ser computados na direção oposta. E portanto o algoritmo acima iria remover as faces visiveis e mostraria as faces ocultas, resultando no efeito oposto ao esperado. E portanto, deve-se conhecer qual a ordenação dos vertices que cada ferramenta usa para definir os triangulos da malha dos modelos.
Então nosso pseudocodigo ficaria da seguinte forma: Vamos passar em nossa cena e filtrar quais faces estão acessíveis para a camera. As que estiverem, vamos mandar para nosso algoritmo de preencher triangulos.
\begin{algorithm}
\caption{Recebe a malha de triangulos em coordenada de mundo, e a camera, e retorna quais sao os triangulos visiveis a partir da posicao da camera}
\begin{algorithmic}
\PROCEDURE{RecortaTriangulos}{$mesh, camera$}
\STATE $triangulos_{visiveis} = $[]
\FOR{cada triangulo em mesh}
\STATE $\vec{AB} = triangulo_b - triangulo_a$
\STATE $\vec{AC} = triangulo_c - triangulo_a$
\STATE $normal_{triangulo} = \vec{AB} \cdot \vec{AC} $
\STATE $baricentro = Vetor(\frac{x_A + x_B + x_C}{3}, \frac{y_A + y_B + y_C}{3}, \frac{z_A + z_B + z_C}{3} )$
\STATE $\vec{BaricentroCamera} = camera - baricentro$
\STATE $cos_{baricentro \angle camera } = \vec{BaricentroCamera} \cdot normal_{triangulo}$
\IF{$cos_{baricentro \angle camera} > 0$}
\STATE $triangulos_{visiveis}$.push(triangulo)
\ENDIF
\ENDFOR
\RETURN $triangulos_{visiveis}$
\ENDPROCEDURE
\end{algorithmic}
\end{algorithm}
E então chamamos para preencher apenas os triangulos recortados por RecortaTriangulos.
Abaixo segue nossa implementação de ambos os algoritmos, tanto z-buffer quanto face-culling.
“A luz e a sombra são os oradores desta arquitetura da verdade, expressando silenciosamente a alma dos objetos nos quais habitam.” - Leonardo da Vinci
Ao pensar na alma dos objetos nos quais habitam sempre me vem a citação de Hermes Trismegisto à seu discipulo Asclépius em mente:
Darkness will be preferred to light, and death will be thought more profitable than life; no one will raise his eyes to heaven ; the pious will be deemed insane, and the impious wise; the madman will be thought a brave man, and the wicked will be esteemed as good. As to the soul, and the belief that it is immortal by nature, or may hope to attain to immortality, as I have taught you, all this they will mock at, and will even persuade themselves that it is false., No word of reverence or piety, no utterance worthy of heaven and of the gods of heaven, will be heard or believed.
Este trecho foi retirado da tradução de um texto grego antigo, um dos poucos salvos por sorte, das inumeras queimas de livros antigos.
Uma visão das antigas tradições filosoficas era que o que chamamos hoje de “espiritualidade” nada distinguia do conhecimento filosófico. E partindo desta forma antiga de ver o conhecimento, a escuridão, era um dos nomes para ignorancia.
O sabio, portanto, era um que preferia à luz.
Mas existia um preeambulo nos sabios do passado do qual os modernos se separaram: a materia.
Para os sábios antigos, a matéria era a projeção mais imperfeita do que estava representado no mundo perfeito das ideias e dos deuses. Por isso, em tantos diálogos de Sócrates, encontram-se analogias com os deuses, pois eles representavam aquilo que era perfeito e, portanto, o alvo humano
“Arte vai continuar como a mais surpreendente atividade da humanidade nascida da dificuldade entre sabedoria e loucura, entre sonho e realidade em nossa mente.” - Magalena Abakanowicz

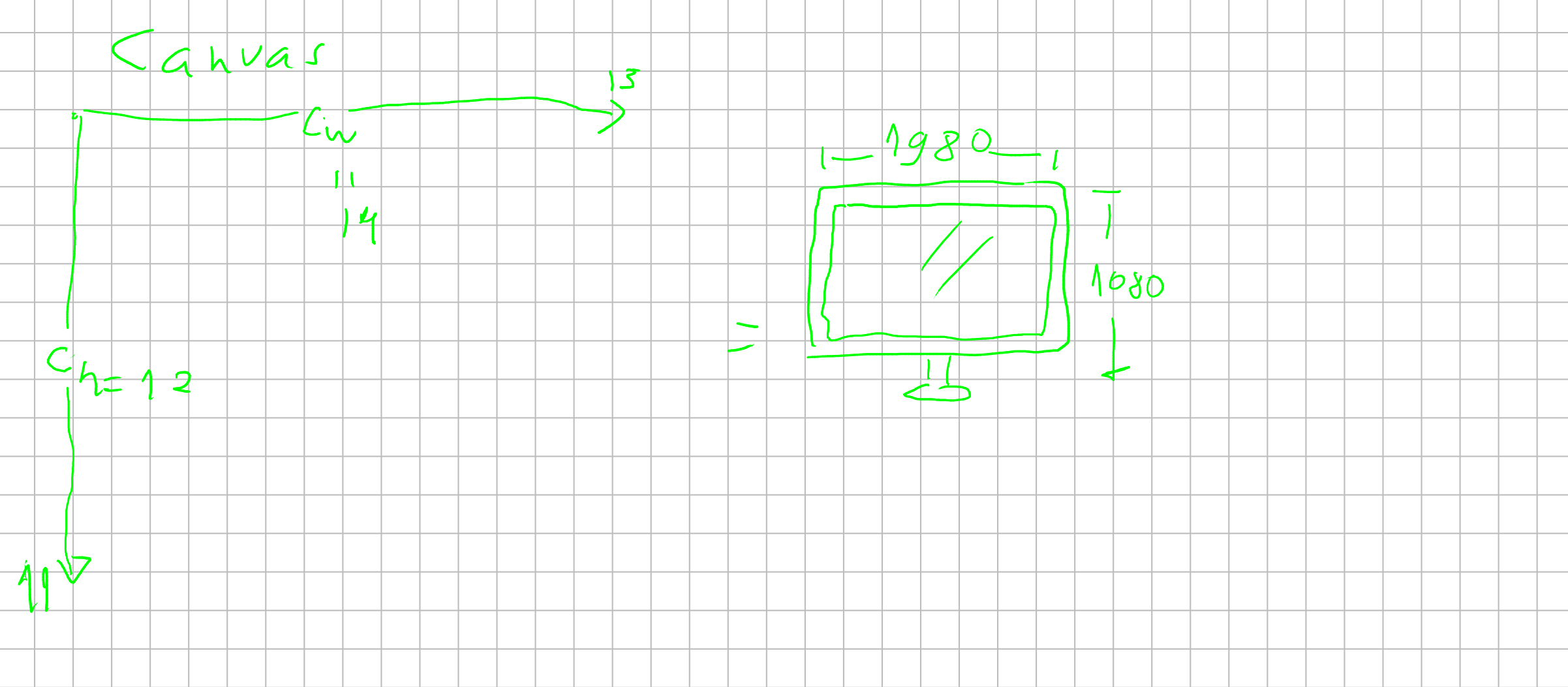 A tela de um computador (como vista no texto de raytracing) é representada como a imagem acima: (eixo \(x\) cresce para direita, e o eixo \(y\) cresce para baixo.
A tela de um computador (como vista no texto de raytracing) é representada como a imagem acima: (eixo \(x\) cresce para direita, e o eixo \(y\) cresce para baixo.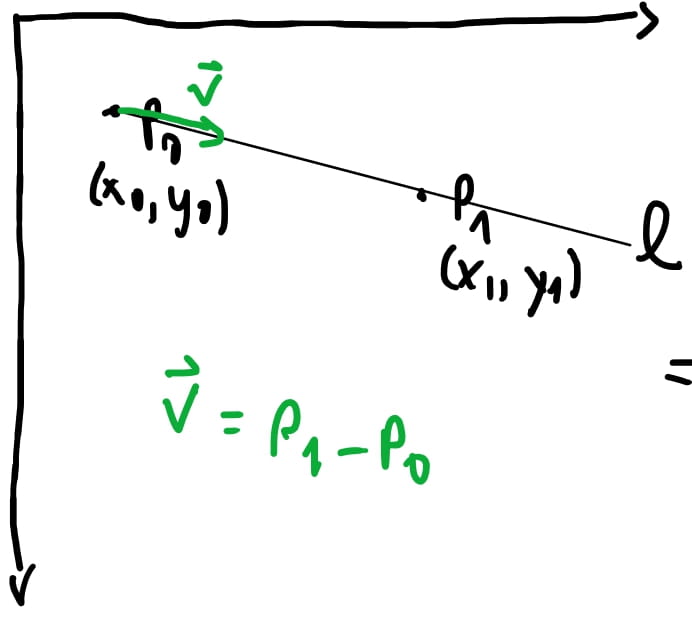
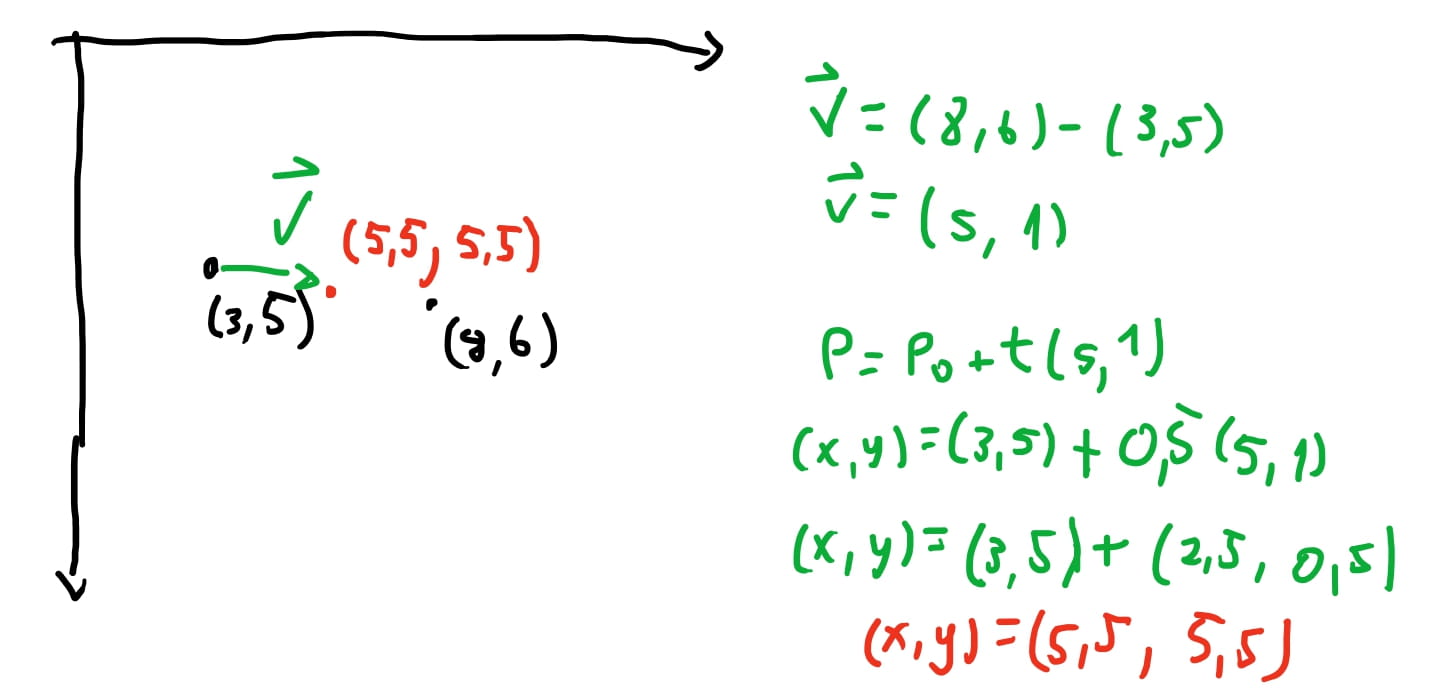 Na imagem acima vemos um exemplo de como usamos esta equação que modelamos para encontrar um ponto na reta. Fizemos \(t = 0.5\) e encontramos um ponto na reta \(l\) em que \(P = (5.5, 5.5)\).
Porem como podemos fazer para encontrar os pixels na tela? Vamos lembrar que o pixel é “discreto”. Quando digo “discreto” digo que é um valor “inteiro”, ou seja, o pixel \((5.5, 5.5)\) não existe na tela, apenas o pixel \((5,5)\). Então se fizéssemos uma função como iterar entre 0 e 1 e incrementar \(0.01\), Iteraríamos mil vezes e repetiríamos muitos valores: Todos valores entre \(5.001\) e \(5.599\) seriam o mesmo pixel. Talvez não pareça tão ruim agora mas imagine que vamos usar esta mesma função para preencher triângulos e no futuro cada polígono tridimensional vai ter milhares de triângulos, então ja imagine o quanto essa função vai fazer o computador trabalhar atoa.
Na imagem acima vemos um exemplo de como usamos esta equação que modelamos para encontrar um ponto na reta. Fizemos \(t = 0.5\) e encontramos um ponto na reta \(l\) em que \(P = (5.5, 5.5)\).
Porem como podemos fazer para encontrar os pixels na tela? Vamos lembrar que o pixel é “discreto”. Quando digo “discreto” digo que é um valor “inteiro”, ou seja, o pixel \((5.5, 5.5)\) não existe na tela, apenas o pixel \((5,5)\). Então se fizéssemos uma função como iterar entre 0 e 1 e incrementar \(0.01\), Iteraríamos mil vezes e repetiríamos muitos valores: Todos valores entre \(5.001\) e \(5.599\) seriam o mesmo pixel. Talvez não pareça tão ruim agora mas imagine que vamos usar esta mesma função para preencher triângulos e no futuro cada polígono tridimensional vai ter milhares de triângulos, então ja imagine o quanto essa função vai fazer o computador trabalhar atoa.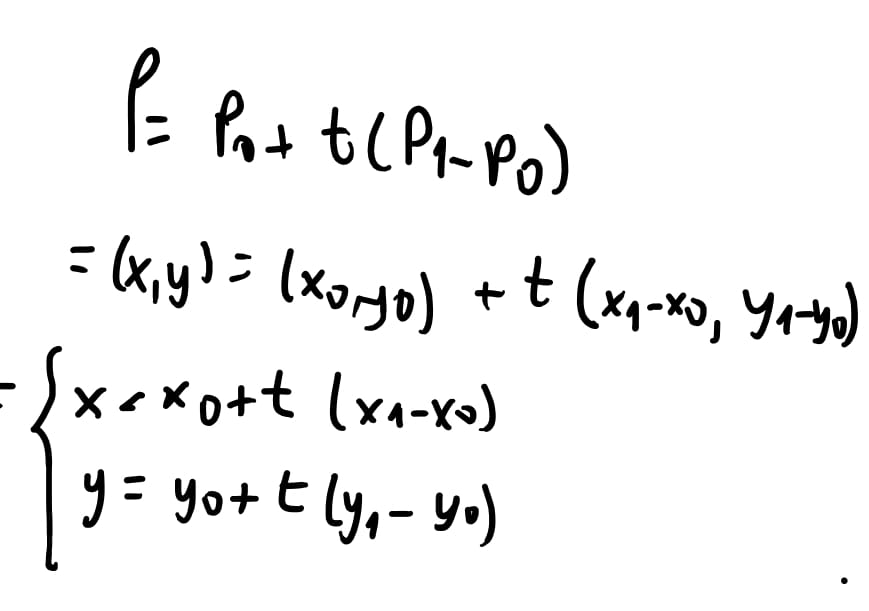 Decompomos então a nossa equação em \((x,y) = (x_0, y_0) + t * ( x_1 - x_0 , y_1 - y_0)\). O motivo dessa subtração é que para encontrar a direção de um ponto para o outro (chamamos essa direção de vetor) fazemos \(ponto Final - ponto Inicial\) e isto nos dá o “vetor” que aponta do ponto inicial para o ponto final.
Decompomos então a nossa equação em \((x,y) = (x_0, y_0) + t * ( x_1 - x_0 , y_1 - y_0)\). O motivo dessa subtração é que para encontrar a direção de um ponto para o outro (chamamos essa direção de vetor) fazemos \(ponto Final - ponto Inicial\) e isto nos dá o “vetor” que aponta do ponto inicial para o ponto final.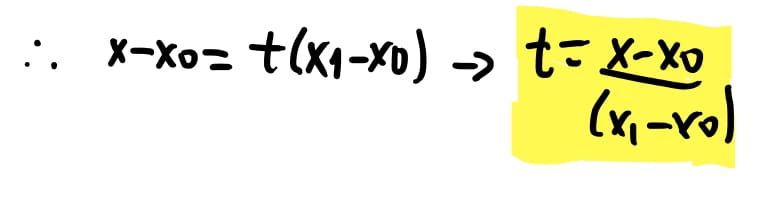 Isolando o \(t\) encontramos que \(t = \dfrac{x - x_0}{x_1 - x_0}\)
Isolando o \(t\) encontramos que \(t = \dfrac{x - x_0}{x_1 - x_0}\)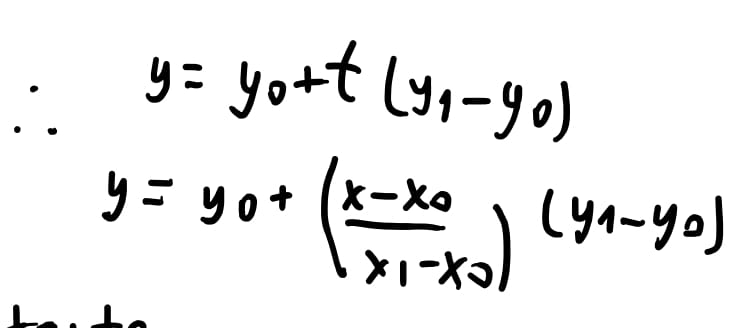 Fazendo a substituição do nosso valor de \(t\) na equação de \(y\) encontramos que \(y = y_0 + \dfrac{x-x_0}{x_1 - x_0} * (y_1 - y_0)\).
Fazendo a substituição do nosso valor de \(t\) na equação de \(y\) encontramos que \(y = y_0 + \dfrac{x-x_0}{x_1 - x_0} * (y_1 - y_0)\). Percebemos também que se fizermos a multiplicação de \(a\) por \((x-x_0)\) restante, encontramos outras constantes: \(y_0\) e \(-a * x_0\). Que vamos chamar de \(b\).
Percebemos também que se fizermos a multiplicação de \(a\) por \((x-x_0)\) restante, encontramos outras constantes: \(y_0\) e \(-a * x_0\). Que vamos chamar de \(b\).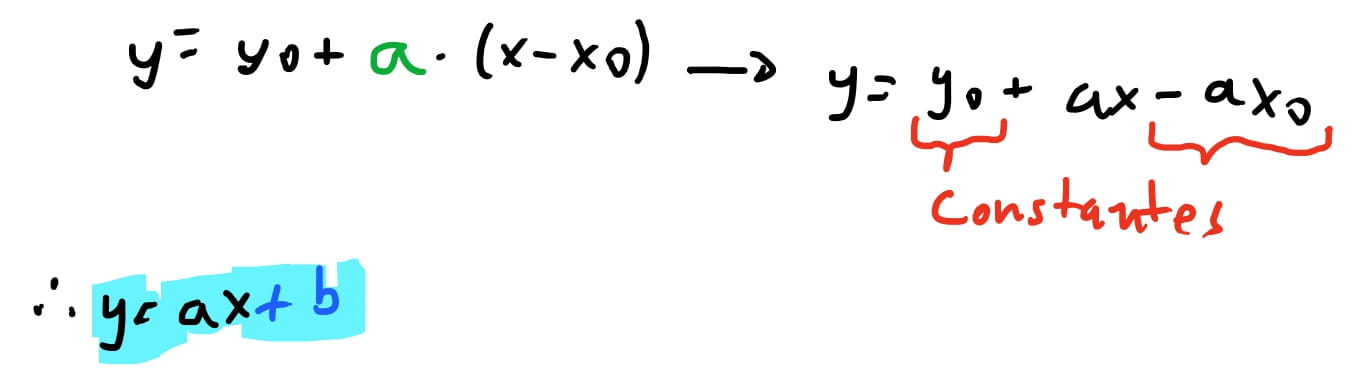 Resultando na equação de reta. Nesta equação conseguimos obter um valor de \(y\) para cada valor de \(x\) entrado.
Vamos para um exemplo
Resultando na equação de reta. Nesta equação conseguimos obter um valor de \(y\) para cada valor de \(x\) entrado.
Vamos para um exemplo
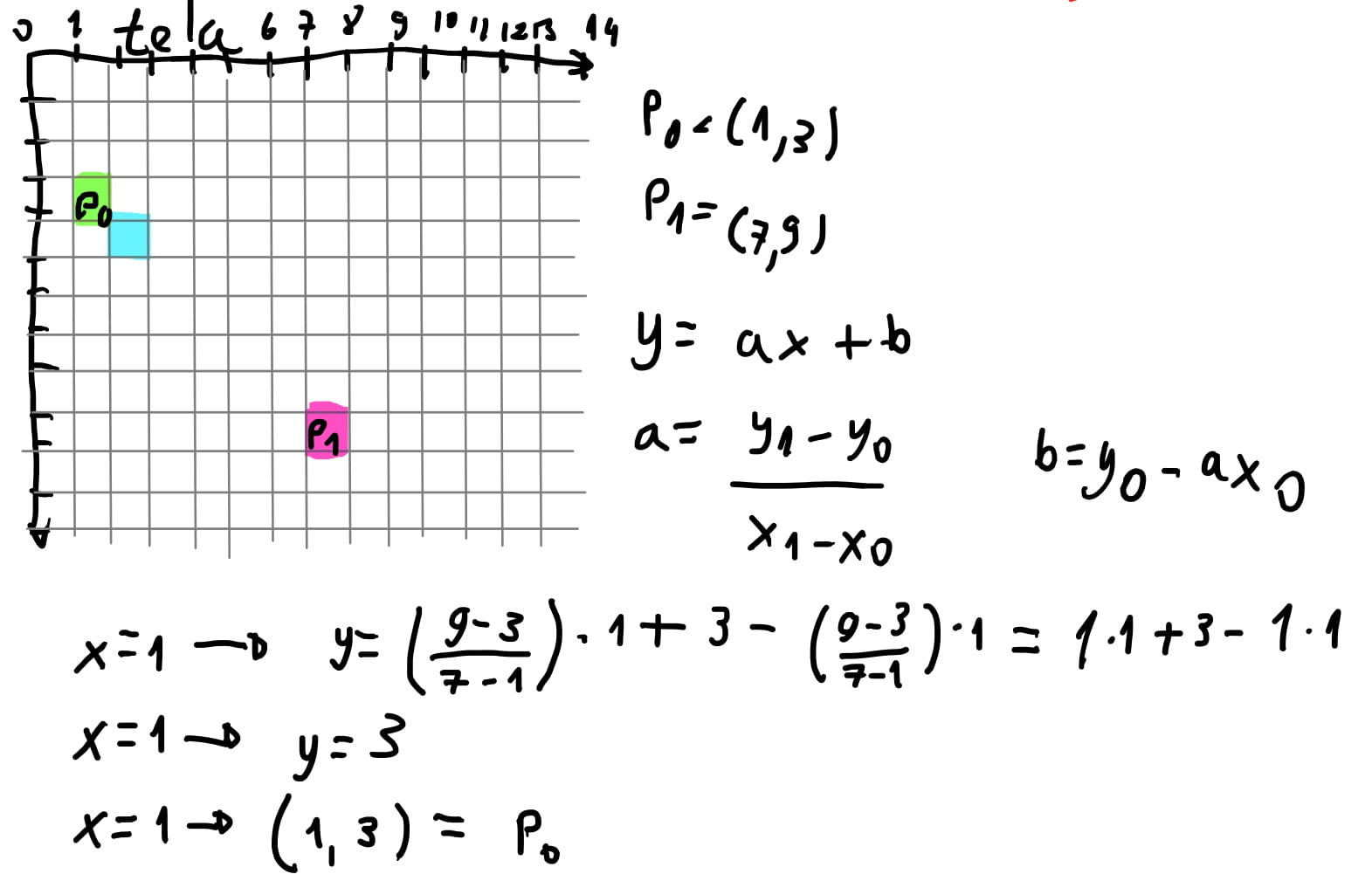 Para \(x = 1\) constatamos que o \(y = 3\), ou seja, confirmamos a posição de \(P_0\).
Para \(x = 1\) constatamos que o \(y = 3\), ou seja, confirmamos a posição de \(P_0\).
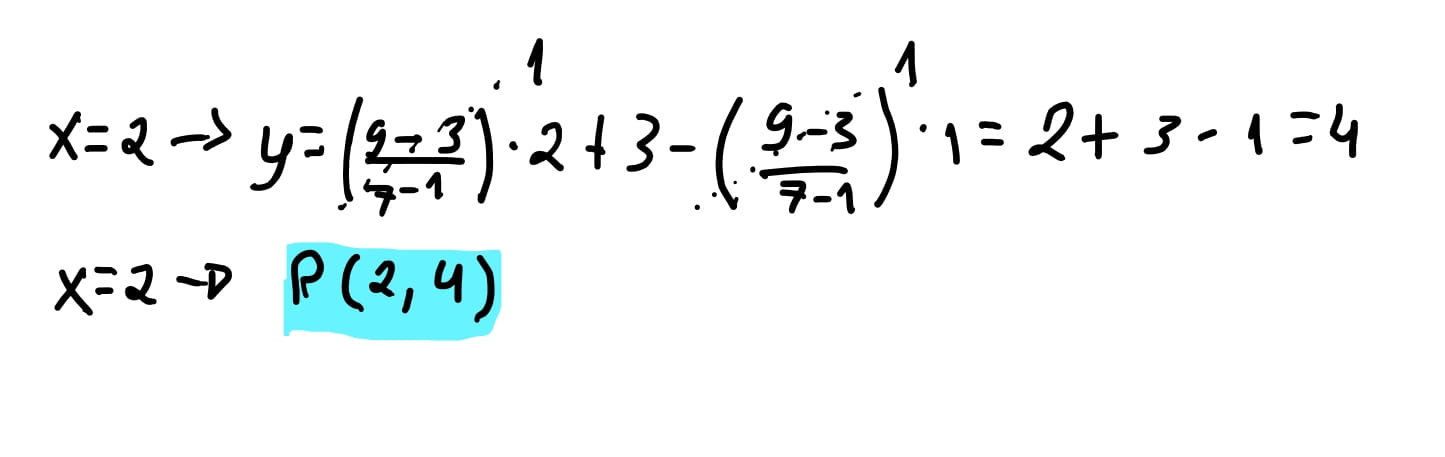
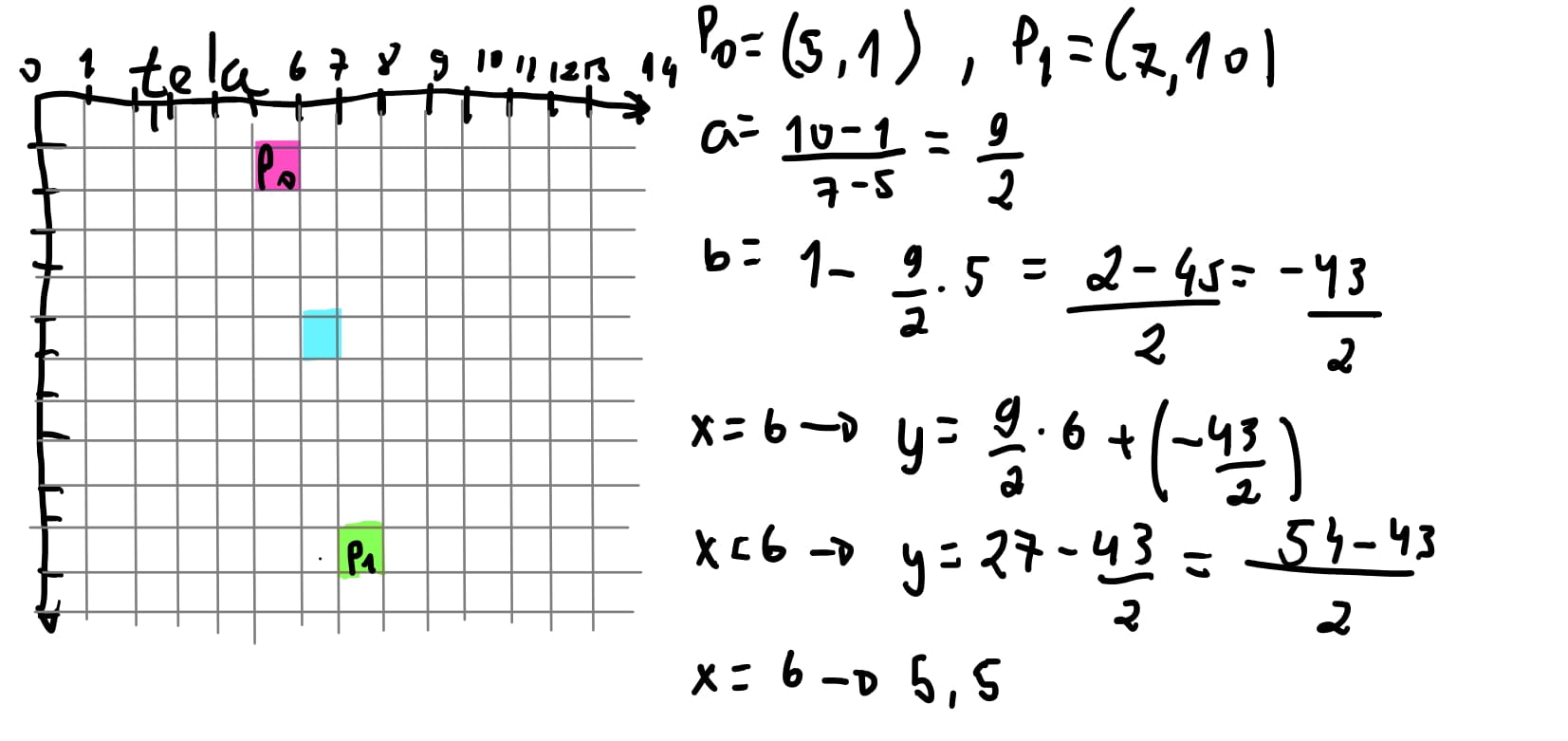 Quanto mais inclinada é a reta, teremos, como no exemplo acima, apenas um valor de \(x\) para vários pixels no eixo \(y\). Se a reta for completamente vertical, ou seja, o valor da coordenada \(x\) do ponto inicial e final é o mesmo, simplesmente não há iteração e logo não há nenhum pixel para ser colorido.
Quanto mais inclinada é a reta, teremos, como no exemplo acima, apenas um valor de \(x\) para vários pixels no eixo \(y\). Se a reta for completamente vertical, ou seja, o valor da coordenada \(x\) do ponto inicial e final é o mesmo, simplesmente não há iteração e logo não há nenhum pixel para ser colorido.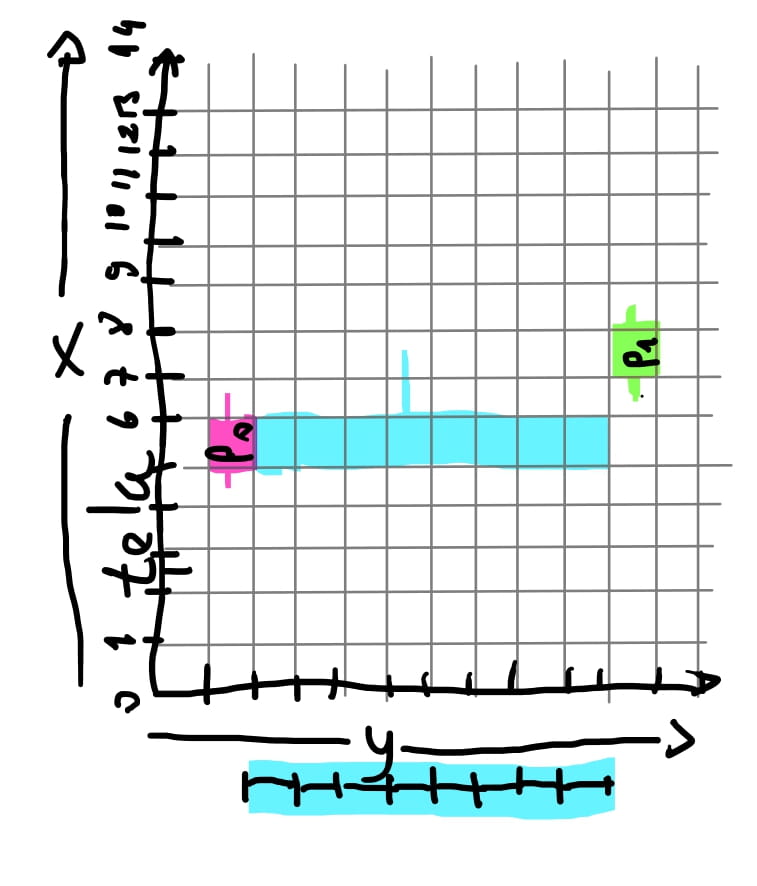
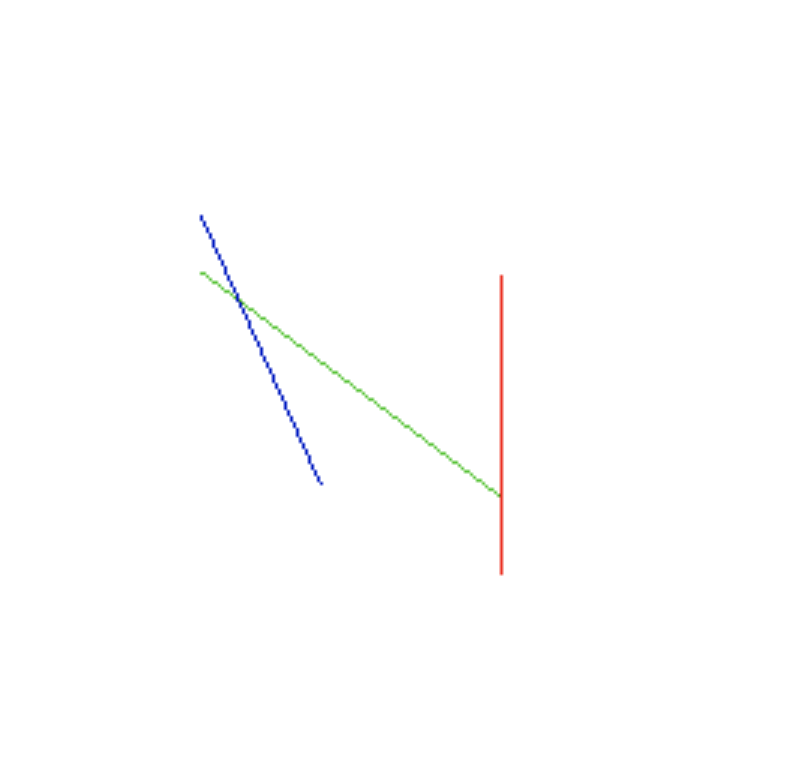

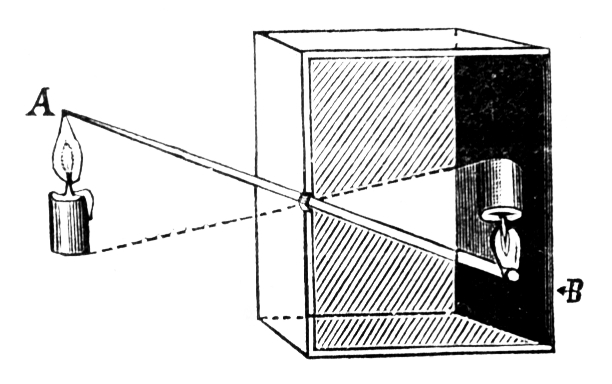
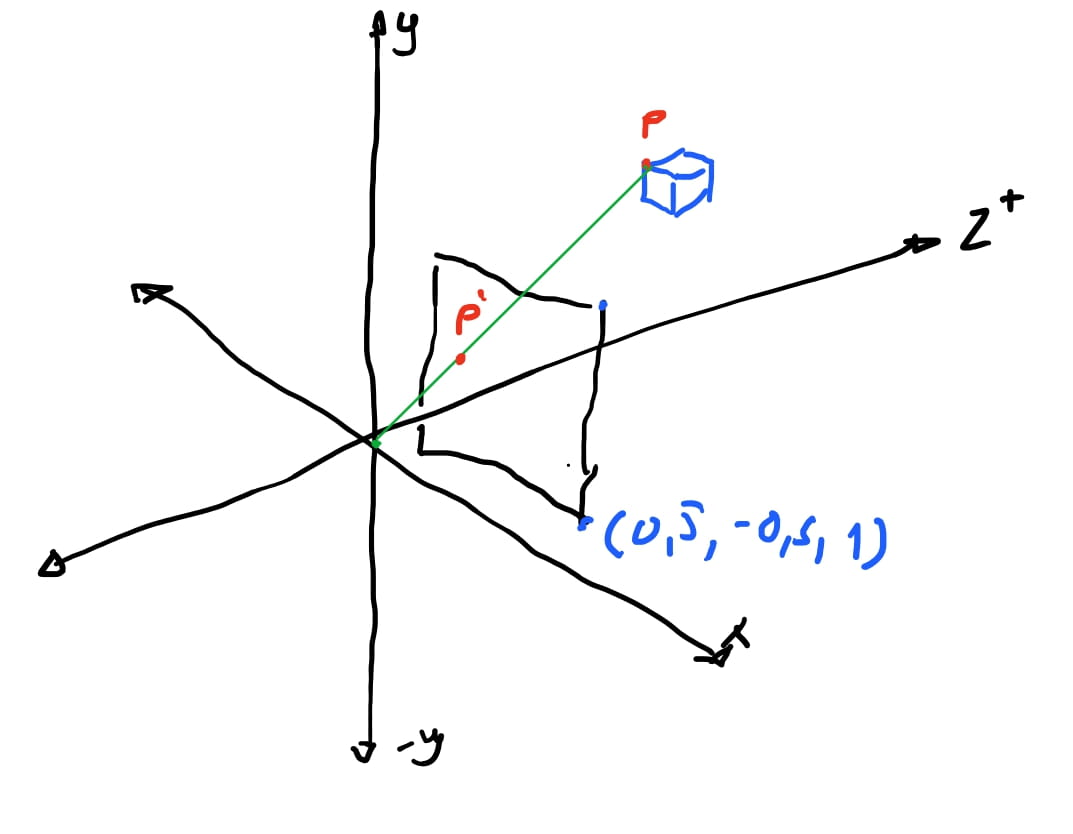 Vamos usar a cena acima: temos um cubo na cena, e temos um plano centralizado em \(z_+\), e a uma distancia \(d = 1\).
Vamos usar a cena acima: temos um cubo na cena, e temos um plano centralizado em \(z_+\), e a uma distancia \(d = 1\).